I'm working with a covid dataset for some python exercises I am working through to try learn. I've got it by doing the normal:
import pandas as pd import numpy as np
df = pd.read_csv("C:/Users/Desktop/Python Short Course/diagnosis.csv")
In this dataset there are 2 columns called BodyTemp and SpO2, what I am looking to try do is show how the results of the columns are similar. So like when the values rise in the BodyTemp column, so does the values in the SpO2 column, that sort of idea. I had thought of maybe doing a bar chart like:
plt.xlabel("BodyTemp") , plt.ylabel("SpO2")
plt.bar(x = df["BodyTemp"], height = df["SpO2"])
plt.show()
but all the bars are very close together and it just doesn't look great, so what would be a better way to do this? Or would there be a better approach to show the visualisation of the distribution of values?
Edit: to show screenshot of graph
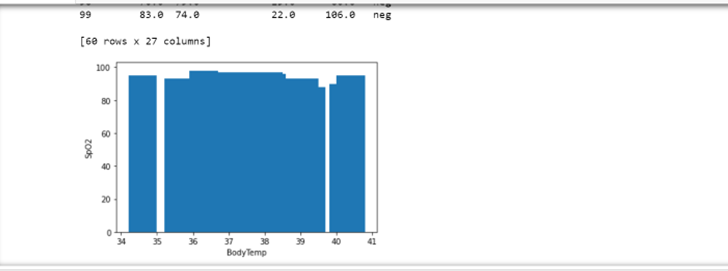
Edit to show data:
| BodyTemp | SpO2 |
|---|---|
| 37.6 | 85 |
| 38.9 | 93 |
| 38.5 | 92 |
| 37 | 80 |
I've added a table showing the first few, there are a whole lot more though but it gives an idea of the data
CodePudding user response:
you need to change the scale of y-axis. try this.
plt.ylim((df['SpO2'].min()-.5, df['SpO2'].max() .5))
If this didn't work, it's probably because there are very small values in the column SpO2. These gaps between the bars may be small values that are distorting the data. Try to remove them from the dataframe.