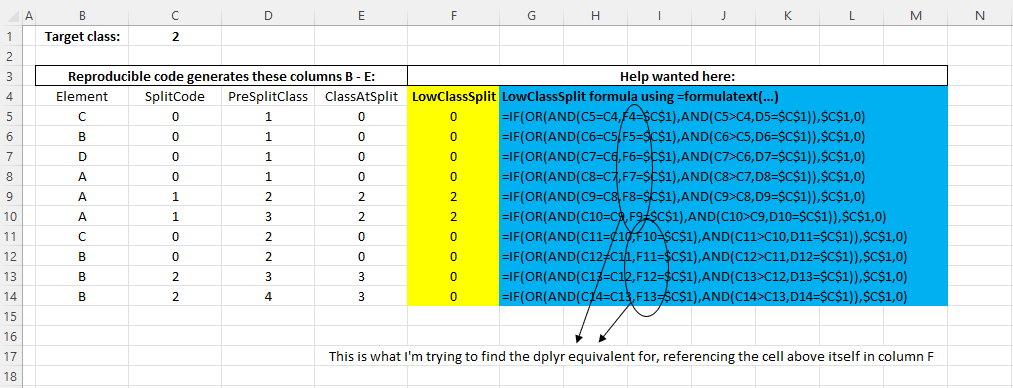
In the reproducible R code shown at the bottom, I'm trying to create a column called LowClassSplit, using R package dplyr, whose value depends on its own value calculated immediately above itself. My attempt to resolve is commented out. Equivalent to the Excel calculations illustrated below and highlighted yellow, where the calculations in each Column F cell refers to its value immediately above itself. The blue cells show the column F calculations using the =FORMULATEXT(...) formula in Excel.
Any recommendations for the functional equivalent in dplyr? Or if not available in dplyr, in base R?
Below is the expected output in R, same as the illustrated Excel example:
# A tibble: 10 x 4
Element SplitCode PreSplitClass ClassAtSplit
<chr> <dbl> <int> <dbl>
1 C 0 1 0
2 B 0 1 0
3 D 0 1 0
4 A 0 1 0
5 A 1 2 2
6 A 1 3 2
7 C 0 2 0
8 B 0 2 0
9 B 2 3 0
10 B 2 4 0
Reproducible code:
library(dplyr)
data <-
data.frame(
Element = c("C","B","D","A","A","A","C","B","B","B"),
SplitCode = c(0,0,0,0,1,1,0,0,2,2)
)
data <- data %>% group_by(Element) %>% mutate(PreSplitClass=row_number()) %>% ungroup()
data %>%
mutate(ClassAtSplit =
case_when(
SplitCode == 0 ~ as.integer(0), # This eliminates checking for > 0
SplitCode > lag(SplitCode) ~ PreSplitClass, # if > previous value
SplitCode == SplitCode ~ lag(PreSplitClass) # if equal (0s are avoided)
)
)
# Below shows where I was going before running into issue of referencing cell above:
# data %>%
# mutate(LowClassSplit =
# case_when(
# SplitCode == 0 ~ as.integer(0),
# (SplitCode == lag(SplitCode) && lagitself == 1)|(SplitCode > lag(SplitCode) & PreSplitClass == 1) ~ 1
# )
# )
Final code including Rui Barrada's posted solution:
library(dplyr)
data <-
data.frame(
Element = c("C","B","D","A","A","A","C","B","B","B"),
SplitCode = c(0,0,0,0,1,1,0,0,2,2)
)
excelCopy <- data %>%
group_by(Element) %>%
mutate(PreSplitClass = row_number()) %>%
ungroup() %>%
mutate(ClassAtSplit =
case_when(
SplitCode == 0 ~ as.integer(0), # This eliminates checking for > 0
SplitCode > lag(SplitCode) ~ PreSplitClass, # if > previous value
SplitCode == lag(SplitCode) ~ lag(PreSplitClass) # if equal (0s are avoided)
)
) %>%
mutate(
LowClassSplit =
case_when(
SplitCode > lag(SplitCode) & SplitCode == 1 ~ PreSplitClass,
SplitCode == lag(SplitCode) & SplitCode == 1 ~ lag(PreSplitClass),
TRUE ~ 0L
)
)
CodePudding user response:
Maybe the following is what the question is asking for.
library(dplyr)
data <-
data.frame(
Element = c("C","B","D","A","A","A","C","B","B","B"),
SplitCode = c(0,0,0,0,1,1,0,0,2,2)
)
data <- data %>%
group_by(Element) %>%
mutate(PreSplitClass = row_number()) %>%
ungroup()
data %>%
mutate(
LowClassSplit =
case_when(
SplitCode > lag(SplitCode) & SplitCode == 1 ~ PreSplitClass,
SplitCode == lag(SplitCode) & SplitCode == 1 ~ lag(PreSplitClass),
TRUE ~ 0L
)
)
#> # A tibble: 10 × 4
#> Element SplitCode PreSplitClass LowClassSplit
#> <chr> <dbl> <int> <int>
#> 1 C 0 1 0
#> 2 B 0 1 0
#> 3 D 0 1 0
#> 4 A 0 1 0
#> 5 A 1 2 2
#> 6 A 1 3 2
#> 7 C 0 2 0
#> 8 B 0 2 0
#> 9 B 2 3 0
#> 10 B 2 4 0
Created on 2022-07-10 by the reprex package (v2.0.1)