I am trying to union two spark data frames with different timestamp values, but I am not able to get separate timestamps. I am getting a single timestamp for all the data, e.g.,
in dataframe1 it is 2022-07-8T05:08:22.395 000
in dataframe2 it is 2022-07-8T05:02:10.757 000,
but in output it is 2022-07-8T05:08:34.651 000
but I am expecting timestamp from dataframe1 and dataframe2.
Any specific reason for this and how I can prevent this?
I use Spark 3.1.2.
Using the following function:
def unionMissing(df1, df2=hist_df):
# Add missing columns to df1
left_df = df1
for column in set(df2.columns) - set(df1.columns):
left_df = left_df.withColumn(column, F.lit(None))
# Add missing columns to df2
right_df = df2
for column in set(df1.columns) - set(df2.columns):
right_df = right_df.withColumn(column, F.lit(None))
# Make sure columns are ordered the same
return left_df.unionAll(right_df.select(left_df.columns))
I have also tried the following, but results were the same.
df = df1.unionByName(df2, allowMissingColumns=True)
dataframe1:
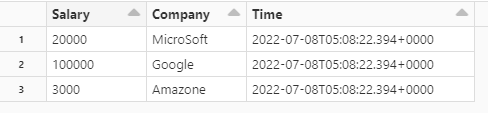
dataframe2:
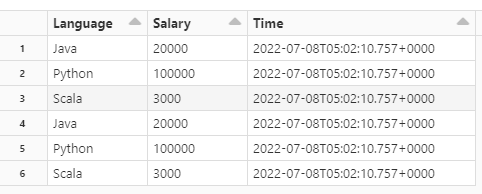
Output:
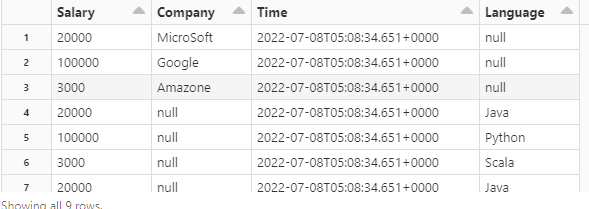
CodePudding user response:
I think the situation is because of spark's lazy evaluation. Here's a test where I was able to replicate your issue and a way to solve it using python's datetime module.
data1_sdf = spark.sparkContext.parallelize([(1, 1)]).toDF(['id1', 'id2']). \
withColumn('spark_currts', func.current_timestamp()). \
withColumn('dttm_currts', func.lit(datetime.datetime.now()))
data1_sdf.show(truncate=False)
# --- --- ----------------------- ------------------------
# |id1|id2|spark_currts |dttm_currts |
# --- --- ----------------------- ------------------------
# |1 |1 |2022-07-11 10:42:00.346|2022-07-11 10:41:44.6466|
# --- --- ----------------------- ------------------------
data2_sdf = spark.sparkContext.parallelize([(2, 2)]).toDF(['id1', 'id3']). \
withColumn('spark_currts', func.current_timestamp()). \
withColumn('dttm_currts', func.lit(datetime.datetime.now()))
data2_sdf.show(truncate=False)
# --- --- ----------------------- --------------------------
# |id1|id3|spark_currts |dttm_currts |
# --- --- ----------------------- --------------------------
# |2 |2 |2022-07-11 10:42:30.703|2022-07-11 10:41:45.162876|
# --- --- ----------------------- --------------------------
data1_sdf.unionByName(data2_sdf, allowMissingColumns=True).show(truncate=False)
# --- ---- ----------------------- -------------------------- ----
# |id1|id2 |spark_currts |dttm_currts |id3 |
# --- ---- ----------------------- -------------------------- ----
# |1 |1 |2022-07-11 10:43:35.629|2022-07-11 10:41:44.6466 |null|
# |2 |null|2022-07-11 10:43:35.629|2022-07-11 10:41:45.162876|2 |
# --- ---- ----------------------- -------------------------- ----
Using current time from datetime module is retains the timestamp after the evaluation.