I have a base_table and a final_table having same columns with plan and date being the primary keys. The data flow happens from base to final table.
Initially final table will look like below:
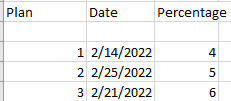
After that the base table will have
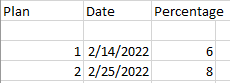
Now the data needs to flow from base table to final table, based on primary keys columns (plan, date) and distinct rows the Final_table should have:
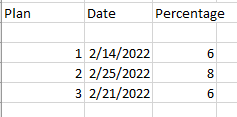
The first two rows gets updated with new values in percentage from base table to final table.
How do we write a SQL query for this? I am looking to write this query in Redshift SQL.
Pseudo code tried:
insert into final_table
(plan, date, percentage)
select
b.plan, b.date, b. percentage from base_table
inner join final_table f on b.plan=f.plan andb.date=f.date;
CodePudding user response:
First you need to understand that clustered (distributed) columnar databases like Redshift and Snowflake don't enforce uniqueness constraints (would be a performance killer). So your pseudo code is incorrect as this will create duplicate rows in the final_table.
You could use UPDATE to change the values in the rows with matching PKs. However, this won't work in the case where there are new values to be added to final_table. I expect you need a more general solution that works in the case of updated values AND new values.
The general way to address this is to create an "upsert" transaction that deletes the matching rows and then inserts rows into the target table. A transaction is needed so no other session can see the table where the rows are deleted but not yet inserted. It looks like:
begin;
delete from final_table
using base_table
where final_table.plan = base_table.plan
and final_table.date = base_table.date;
insert into final_table
select * from base_table;
commit;
Things to remember - 1) autocommit mode can break the transaction 2) you should vacuum and analyze the table if the number of rows changed is large.
Based on your description it is not clear that I have captured the full intent of you situation ("distinct rows from two tables"). If I have missed the intent please update.
CodePudding user response:
You don't need an INSERT statement but an UPDATE statement -
UPDATE final_table
SET percentage = b.percentage
FROM base_table b
INNER JOIN final_table f ON b.plan = f.plan AND b.date = f.date;