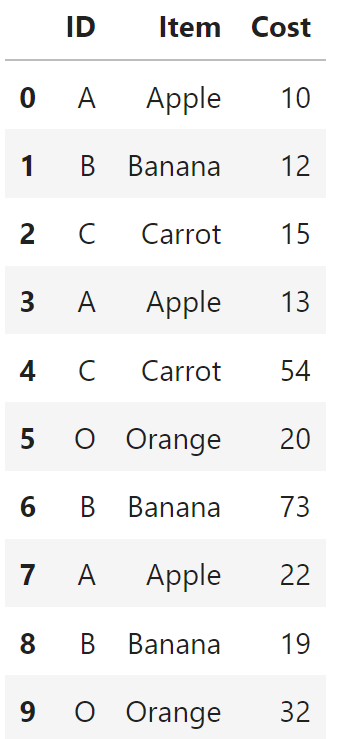
Suppose I have the following dataframe:
data = {'ID': ['A', 'B', 'C', 'A', 'C', 'O', 'B', 'A', 'B', 'O'], 'Item':['Apple','Banana','Carrot','Apple', 'Carrot', 'Orange', 'Banana', 'Apple', 'Banana', 'Orange'], 'Cost':[10, 12, 15, 13, 54, 20, 73, 22, 19, 32]}
dataframe = pd.DataFrame(data)
dataframe
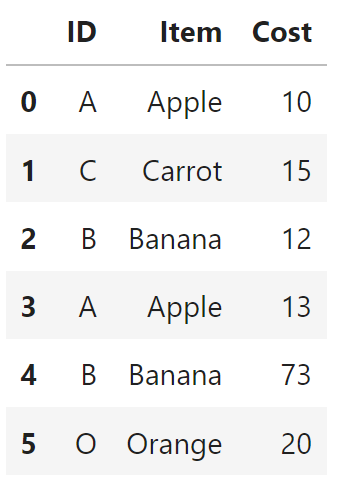
And I want to replace the cost of the current item with the cost of the previous item using Pandas, with the first instance of each item being deleted. So the above dataframe would become
data2 = {'ID': ['A', 'C', 'B', 'A', 'B', 'O'], 'Item':['Apple', 'Carrot', 'Banana', 'Apple', 'Banana', 'Orange'], 'Cost':[10, 15, 12, 13, 73, 20]}
dataframe2 = pd.DataFrame(data2)
dataframe2
What's a good way to do it?
CodePudding user response:
Use groupby and head with a negative number to exclude the last occurrence of each item:
>>> dataframe.groupby('Item').head(-1)
ID Item Cost
0 A Apple 10
1 B Banana 12
2 C Carrot 15
3 A Apple 13
5 O Orange 20
6 B Banana 73
CodePudding user response:
You can use groupby on Item as well. This gives you output in the same order you expected
data['Cost'] = data.groupby('Item')['Cost'].shift(fill_value=0)
data[data['Cost'] != 0]
This gives us expected output:
ID Item Cost
3 A Apple 10
4 C Carrot 15
6 B Banana 12
7 A Apple 13
8 B Banana 73
9 O Orange 20