Input:
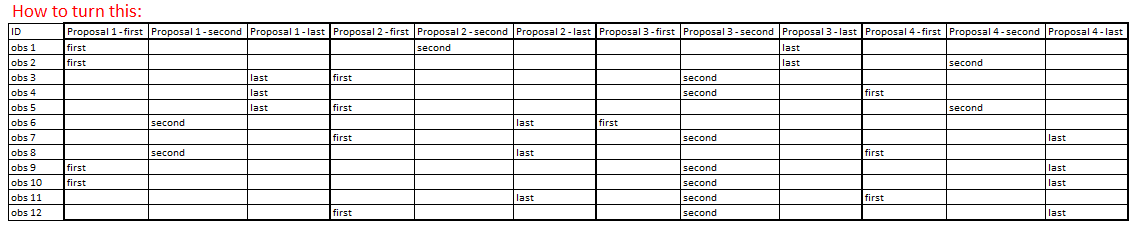 Output:
Output:
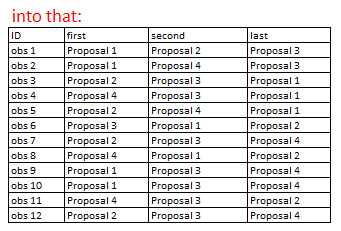
here's the data:
d = {'Morning': ["Didn't answer", "Didn't answer", "Didn't answer", 'Morning', "Didn't answer"], 'Afternoon': ["Didn't answer", 'Afternoon', "Didn't answer", 'Afternoon', "Didn't answer"], 'Night': ["Didn't answer", 'Night', "Didn't answer", 'Night', 'Night'], 'Sporadic': ["Didn't answer", "Didn't answer", 'Sporadic', "Didn't answer", "Didn't answer"], 'Constant': ["Didn't answer", "Didn't answer", "Didn't answer", 'Constant', "Didn't answer"]}
Morning Afternoon Night Sporadic Constant
0 Didn't answer Didn't answer Didn't answer Didn't answer Didn't answer
1 Didn't answer Afternoon Night Didn't answer Didn't answer
2 Didn't answer Didn't answer Didn't answer Sporadic Didn't answer
3 Morning Afternoon Night Didn't answer Constant
4 Didn't answer Didn't answer Night Didn't answer Didn't answer
I want the output to be:
d = {"Time of the day": ["Didn't answer", "['Afternoon', 'Night']", "Sporadic", "['Morning', 'Afternoon', 'Night', 'Constant']", "Night"]}
Time of the day
0 Didn't answer
1 ['Afternoon', 'Night']
2 Sporadic
3 ['Morning', 'Afternoon', 'Night', 'Constant']
4 Night
so if there's no answer in every column in a row, the value in the new data frame would be "Didn't answer" and if there's at least one answer like "night", the value in the new data frame would be "night" and if there are multiple answers like " Morning", "Night" the value in the new data frame would be a list of the answers
CodePudding user response:
There are probably prettier ways to do this but this would be one way:
def extract_valid_cols(row):
# collect all non-"Didn't answer"-values in row
valid_cols = [col for col in row if col != "Didn't answer"]
# return those, except when there are none, then return "Didn't answer"
return valid_cols if valid_cols else ["Didn't answer"]
# apply the defined function row-wise
df["Time of the day"] = df.apply(extract_valid_cols, axis=1)
> Morning ... Time of the day
0 Didn't answer ... [Didn't answer]
1 Didn't answer ... [Afternoon, Night]
2 Didn't answer ... [Sporadic]
3 Morning ... [Morning, Afternoon, Night, Constant]
4 Didn't answer ... [Night]
Putting everything in lists for consistency but if you really want single values then you can add a check if length of list is 1 and if it is just return that item.
CodePudding user response:
You can use:
df["ToD"] = (df.replace("Didn't answer", np.nan).stack().groupby(level=0)
.apply(lambda x: [i for i in x] if len(x) > 1 else x.iloc[0])
.reindex(df.index, fill_value="Didn't answer"))
Output:
>>> df["ToD"]
0 Didn't answer
1 [Afternoon, Night]
2 Sporadic
3 [Morning, Afternoon, Night, Constant]
4 Night
Name: ToD, dtype: object
CodePudding user response:
here is one way
data = pd.DataFrame(d)
def summarize(x):
if len(x.unique())==1:
if x.unique()==["Didn't answer"]:
return "Didn't answer"
else:
x = list(x.unique())
x.remove("Didn't answer")
return x
data.apply(summarize, axis = 1)
Then you get:
0 Didn't answer
1 [Afternoon, Night]
2 [Sporadic]
3 [Morning, Afternoon, Night, Constant]
4 [Night]
dtype: object
CodePudding user response:
You can use pd.apply to get the data in the format you expect :
def get_values(row):
row_set = set(row.values)
if len(row_set) == 1:
return (list(row_set)[0])
elif("Didn't answer" in row_set):
row_set.remove("Didn't answer")
if(len(row_set) == 1):
return (list(row_set)[0])
return(list(row_set))
df["Time of the day"] = df.apply(get_values,axis=1)
This gives us the expected output :
0 Didn't answer
1 [Night, Afternoon]
2 Sporadic
3 [Night, Morning, Afternoon, Constant]
4 Night