I have a pandas data frame to be read from excel range C54:Q66. Now there are multiple datasets in this .Please see figure.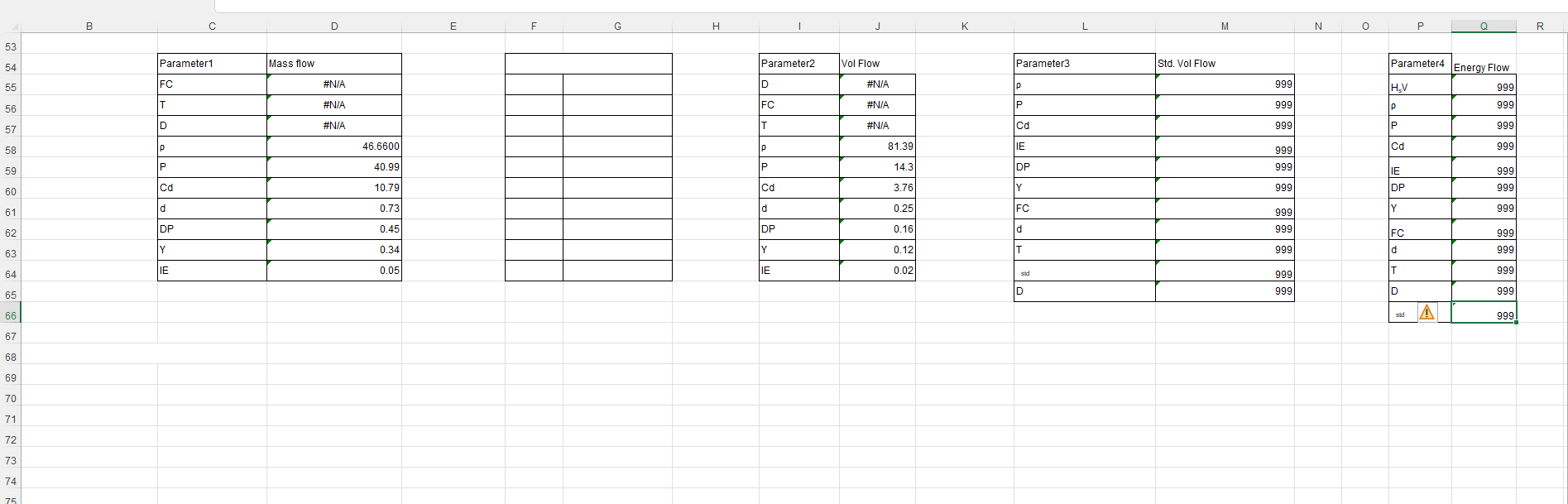
I want to read the main dataframe (Excel Range C54:Q66) once only and the split the dataframes in 4 separate dataframes like:
dataframe_1 = Excel Range (C54:D64)
dataframe_2 = Excel Range (I54:J64)
dataframe_3 = Excel Range (L54:M65)
dataframe_4 = Excel Range (P54:Q66)
Can you please recommend how to do this in Python using pandas. I know one way is to read these data frame individually from excel file but it takes a lot of time to read the file 4 times and I also know it is inefficient. I know you experts will have an efficient way of achieving this. THANKS!
CodePudding user response:
From 
The following code shows how you can parse tables in the same sheet.
usecols: int, str, list-like, or callable default None
If None, then parse all columns.
If str, then indicates comma separated list of Excel column letters and column ranges (e.g. “A:E” or “A,C,E:F”). Ranges are inclusive of both sides.
If list of int, then indicates list of column numbers to be parsed.
If list of string, then indicates list of column names to be parsed.
If callable, then evaluate each column name against it and parse the column if the callable returns True.
Returns a subset of the columns according to behavior above.
xl = pd.ExcelFile("data.xlsx")
df1 = xl.parse(sheet_name=0, header=1, usecols=[1, 2, 3])
df2 = xl.parse(sheet_name=0, header=1, usecols=[6, 7, 8])
df1 output:
| index | col1 | col2 | col3 |
|---|---|---|---|
| 0 | x | x | x |
| 1 | y | y | y |
df2 output:
| index | col4 | col5 | col6 |
|---|---|---|---|
| 0 | a | a | a |
| 1 | b | b | b |