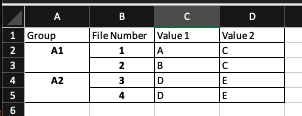
I have a multi index pandas df that looks like the image below. The Group is the main index. Each group represents a group of duplicate files. The file number is a unique identifier for each file. Value 1 and Value 2 are metadata fields in this example.
What I would like to do is find instances where ANY metadata across a group is inconsistent.
For example, in the below image, Group 1 would return because File Numbers 1 and 2 in group A1 have differing metadata under 'Value 1' - so I would want that group to return. Group A2 on the other hand wouldn't return as the metadata IS consistent.
Is there a way to generate this dataframe?
df = pd.read_csv('files.csv', index_col = ['Group', 'File Number'])
CodePudding user response:
You can use groupby_nunique and broadcast the output to all rows. Finally, find rows where at least one value is not consistent:
out = df[df.groupby(level='Group').transform('nunique').ne(1).any(axis=1)]
print(out)
# Output
Value 1 Value 2
Group File Number
A1 1 A C
2 B C
CodePudding user response:
Use groupby with 
Now, using df.groupby('Group').nunique()
gives
Value1
Group
A1 2
A2 1