I have a dataframe with 2 columns like the following:
| ColA | COLB |
|---|---|
| ABC | Null |
| Null | a |
| Null | b |
| DEF | Null |
| Null | c |
| Null | d |
| Null | e |
| GHI | Null |
| IJK | f |
I want to categories the “COLB” based on the “COLA” so that the final output look like :
| ColA | COLB |
|---|---|
| ABC | a,b |
| DEF | c,d,e |
| GHI | Empty |
| IJK | f |
How can I do this using pandas ?
CodePudding user response:
Lets start by creating the DataFrame:
df1 = pd.DataFrame({'ColA'['ABC',np.NaN,np.NaN,'DEF',np.NaN,np.NaN,np.NaN,'GHI','IJK'],'ColB':[np.NaN,'a','b',np.NaN,'c','d','e',np.NaN,'f']})
Next we fill all NaN values with previous occurence:
df1.ColA.fillna(method='ffill',inplace=True)
Then we identify columns with empty colB:
t1 = df1.groupby('ColA').count()
fill_list = t1[t1['ColB'] == 0].index
df1.loc[df1.ColA.isin(fill_list),'ColB'] = 'Empty'
Finally group by and join colB:
df1 = df1.dropna()
df1.groupby('ColA').apply(lambda x: ','.join(x.ColB))
Output:
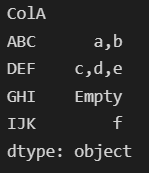
CodePudding user response:
use for loop for modify and then groupby
(I suppose that your null values are string. if it is false you can first replace them with string value with replace method in dataframe)
import pandas as pd
for i in range(1,len(df)):
if df.ColA.loc[i] == 'Null':
df.ColA.loc[i] = df.ColA.loc[i-1]
df = df.groupby(by=['ColA']).aggregate({'ColB': lambda x: ','.join(x)})