I managed to do most of my conversion in VBA Macro (Word > txt) but some changes were made also that I could not forego or get around. Unfortunately, I had not been in the habit of using styles and precise formatting in my docs... (Which is why a PanDoc conversion did not "pan" out well, if you'll excuse the pun.)
In my docs, I was using bold text/lines for in-text titles (not Heading 2 alas) but as I was converting mid-sentence one or two-word bold phrases into phrases to go between double square brackets, the makeshift titles/headings were also changed to [[some title]] format in the process.
With Find and Replace (a batch script that goes through all files in a folder would also do), I would like to search for each and any number of instances of CRLF [[some title CRLF]]CRLF and replace the brackets with ** (to make the title bold), or perhaps ## to make the headings I was missing back in MS Word (I would of course need the line breaks as well).
For better understanding, please see attached picture here:
I am fairly sure that all instances are similarly syntaxed. If not, I may be able to tailor your regex code to differing instances later on.
As you can see, I was trying to do it in two steps but that's not good, because the second step (which I couldn't even get right) would propably have altered other texts I need intact (there must be sentences that start with double brackets after CRLF). I would need the two steps in one so that only the targeted double bracketed text would be changed to bold or Heading 2.
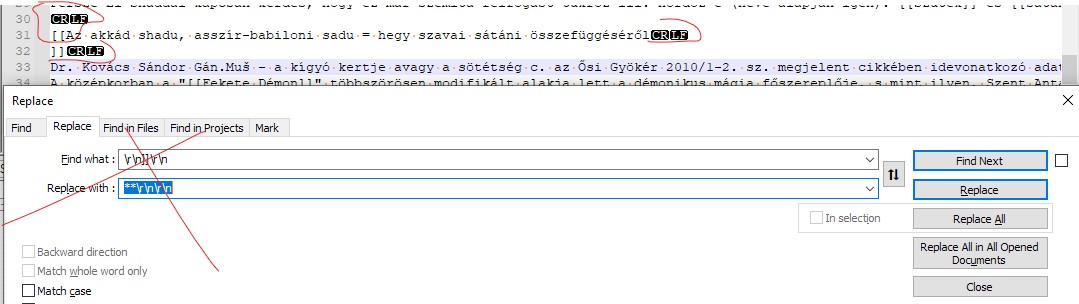
Basically what I could not do is: find the proper regex solution for matching double CRLF-ed and square-bracketed text for any number of words than may occupy more than one line and starts with a capital letter. I would need an empty line above and below the title as indicated in the image (the VBA macro somehow made two instances of CRLF and carried the brackets to a new line, which I do not like, either).
EDIT. In the meantime I managed to cook something up but now I couldn't insert the CRLF in front of the match string. At this point this is not enough as other instances are also changed, even lowercase in-line items, for some reason...
Regex:
\[\[([A-Z][\S\s] ?)\]\]
Substitution:
## $1\r\n
https://regex101.com/r/mH6B9N/1
Since then, I made improvements towards what I wanted (I had to test in NotePad and not Regex101, for different results), but now in multiple documents I have found match across spill-over lines, as described in here: Single line regex search in Notepad Is it possible that I cannot do what I want? The problem is having non-title text strings having line-break, double brackets and capitalized letters.
What it looks like in other documents: See here. I circled around with red in image for clarification. See also: https://regex101.com/r/8XsIGx/1 Is it possible to match a certain word like "címnél" and not execute on that match if that word is present in a line?
{kind=link}
Thanks very much in advance,
F.
CodePudding user response:
You can use
(?s)\R\K\[\[((?:(?!\[\[|]]).)*)\R*]](?=\R)
Replace with ## $1. See the regex demo.
Details:
(?s)- equivalent of the.matches newline option\R- a line break sequence\K- omit the text matched so far (the newlines)\[\[- a[[text((?:(?!\[\[|]]).)*)- Group 1: any char, as many as possible occurrences, that does not start a[[or]]char sequence\R*- zero or more line breaks]]- a]]text(?=\R)- immediately to the right, there must be a line break.