We are adapting to trunk-based development with release-candidate branches. (at the moment we are using trunk-based development, but without release candidate, which is not sufficient anymore)
There is nice description on google: 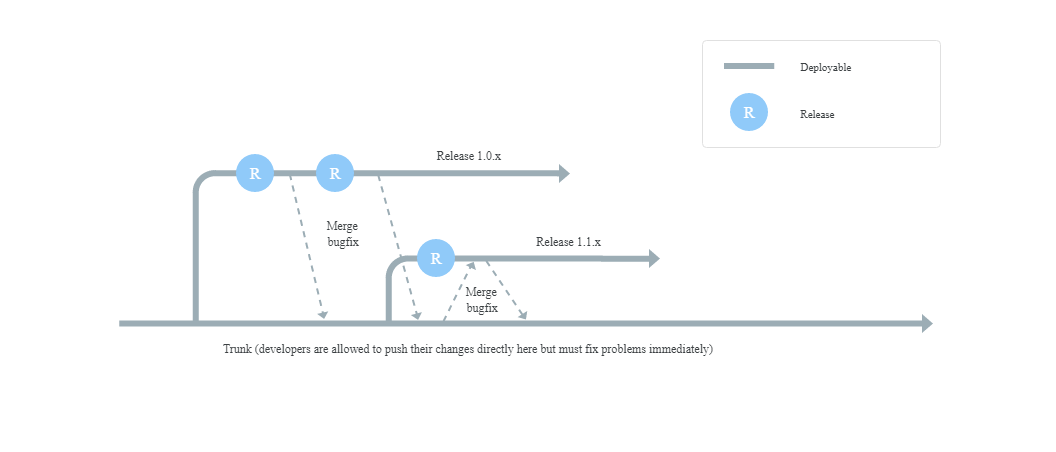
The challenge we have is how to merge bugfix into several Release branches.
Imagine this situation:
- You create Release 1 (similar to 1.0.0 in picture)
- You do several changes to Trunk
- You publish Release 1 to Production
- You create Release 2 (similar 1.1.0 in picture)
- You do several changes to Trunk
Now you find out that there is critical bug in Release 1:
- You create bugfix from latest commit in Release 1
- You merge it back to Release 1 (thus creating 1.1) and then you merge Release 1.1 to Trunk
- You happily publish Release 1.1 to Production
So far all of the above is complient with the picture from Google.
However now is the question how to get the same bugfix to Release 2. (it does not matter if Release 2 is on production or not). You cannot just merge Trunk to Release 2 - some untested changes were made. So the recommended approach is to cherry-pick bugfix from trunk and merge it to Release 2. Altough that would work, it looks a bit human error-prone (not picking everything or not doing it correctly the visibility of what is merged in history is also not easy to see).
I would personally merge directly the Hotfix branch (that originated from Release 1) to Release 2 (therefore creating Relase 2.1 with bugfix). However all references about trunk-based development with release branches are mentioning cherry picking from Trunk and not merging the bugfix directly.
Am I missing something? Why is cherry picking better/more used solution than just merging the bugfix?
CodePudding user response:
This is the mistake, in my opinion:
Now you find out that there is critical bug in Release 1:
- You create bugfix from latest commit in Release 1
People do this for expediency, but the "correct" method is to create the bug fix as a new branch, whose parent commit is the commit in which the bug was introduced.
That is:
tag:v1
|
I--J <-- release-oriented-items-for-v1
/
...--B--C---------G--H <-- mainline
\ /
D--E--F [feature, originally]
Now suppose the actual bug was introduced in commit E, during the implementation of the feature.
The "correct" way to fix this is not to add fixes at (after) H and J but rather to add it immediately after commit E, like this:
tag:v1
|
I--J <-- release-oriented-items-for-v1
/
...--B--C---------G--H <-- mainline
\ /
D--E--F [feature, originally]
\
K <-- fix1234
Branch fix1234 (i.e., commit K) can now be easily merged into every downstream release—well, as easily as any development since E makes it, anyway.
(Read the next two paragraphs in parallel, and merge them in your head.)
Note that if—as does occur in practice—it's necessary to make the initial hotfix as a follow-on commit to J, we can still cherry-pick that fix back (so that it comes just after E) to form the fix1234 branch, which we can then forward-merge into every release (including the v1 release branch, if only to show that yes, the fix is now included in future v1-based releases). And, if the bug no longer appears, you can choose to merge with -s ours, or not bother to merge at all, based on how you feel about using the "merge indicates bug is fixed" idea.
See also Raymond Chen's series of blog posts describing this same idea. Note that this general plan, "go back in time and fix the bug and then merge the fix forward in time", works for all the bug cases, and doing the "cherry-pick back in time so that we can merge forward" technique works in all the bug cases. The fix need only be merged in any commit that is a descendant of the bug, and does need to be merged in every release that is a descendant of the bug, and the fact that it is or is not merged tells you whether the bug is or is not fixed.
CodePudding user response:
If I were using this strategy, I would do what you suggest: I would either merge the hotfix branch from release1 into release2, or perhaps even just merge release1 into release2 after it's done. From there you only have to do one merge of release2 back into trunk, rather than two, and the additional cherry-picks wouldn't be needed. In general, I always prefer merging when possible, and resorting to cherry-picking only when necessary. IMHO having duplicate similar commits in the repo history should be avoided whenever possible, because it adds unnecessary complexity and oftentimes causes additional merge conflicts to deal with. (Which are easy to resolve, but they do take some measurable amount of extra time.)
I can think of 2 scenarios where cherry-picks might be helpful:
- If the bug fix went into
trunkbefore someone realized it also needed to go intorelease1, then cherry-picking the fix commit(s) intoreleasewould make sense (either via ahotfixbranch or directly). At this point you'll still have 2 similar copies of the commit(s) in the repo but there isn't much you can do about that. From there though, I would still mergerelease1back down intorelease2instead of also cherry-picking the fixes intorelease2, which would just create an unnecessary third copy of the commits. - In the case where you are supporting multiple releases in Production, and not all hotfixes are merged back into
trunk, then cherry-picking fixes into somereleasebranches, and perhapstrunkwould make sense. I don't think this is your scenario, or even the scenario that this branching strategy is designed for.
Side note that is almost a joke: I can think of a (somewhat pessimistic) 3rd reason that cherry-picking might be suggested here too. If you do branch merges as you and I are suggesting here, then this branching strategy is pretty much the same thing as Git Flow, except without the extra 3rd branch called master or main to act as a placeholder for "the current commit that is in Production". A lot of people (and companies) like to create their own branching strategies, and many of them inevitably use Git Flow as a comparison and need a way to differentiate themselves from it. In Git Flow the main branch is conceptionally optional if you don't want to point it to the Production commit and remember it another way for hotfixes (like you're doing). After that, the only obvious way this strategy differs from Git Flow is by suggesting cherry-picking instead of merging. Maybe it's a tough pill to swallow taking all the energy to define your own branching strategy only to find out that it's actually Git Flow with some minor tweaks. (IMHO this appears to be shockingly common.)