I have a lot of pdfs (same layout) and I want to extract the data from them and add them to a df with 3 columns. Also, I want the script to run until all the pdfs in the folder are inserted. The answers I've found so far aren't useful.
This is a pdf sample. I want the amounts in the red shape.
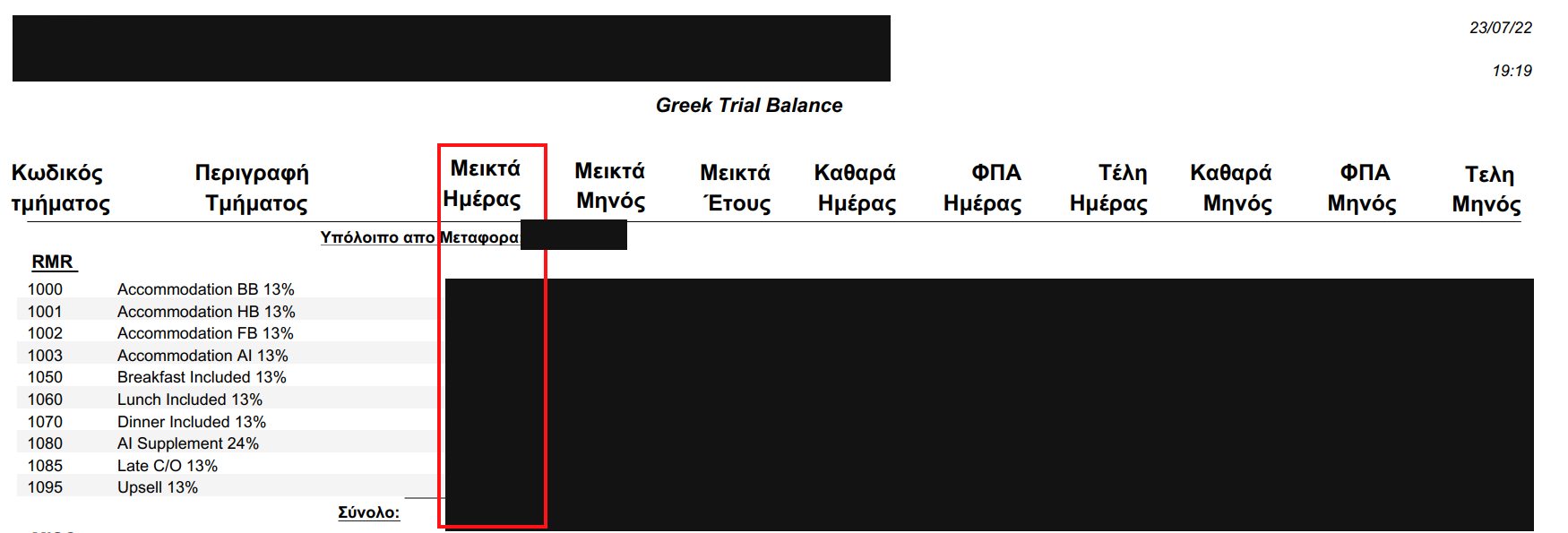
The data are department incomes and I want the table to look like this:
| Date | Department | Amount |
|---|---|---|
| 1/7/21 | Accomodation AI 13% | 3000 |
| 1/7/21 | Accomodation HB 13% | 1500 |
| 1/7/21 | Restaurant #2 24% | 2500 |
CodePudding user response:
If this is for a recurring accounting process I would strongly suggest getting good software (such as Adobe or Simpo PDF Converter) that first converts the pdf to a csv file and then you can use the pandas method read_csv
This is the cleanest approach in my 10 years of accounting/finance/programming as these pdf files tend to change and then break everything. However, to fully answer your question it can be done with the help of Java and the python module tabula. To do it this way...
- Install Java
- Install the python module tabula: pip install tabula-py
- Use the below code which will likely require some tweaking
import pandas as pd
import os
import glob
import jdk
from tabula import read_pdf
# load in all your files
path = '<path where pdf files are>'
pdf_files = glob.glob(os.path.join(path, "*.pdf"))
for file in pdf_files:
# Use the tabula read_pdf, you may need to adjust the encoding and pages
df = tabula.read_pdf(file, encoding='utf-8', pages='1')
# Let x be a string that we will use to name each dataframe. Here I am starting at the 20th character up to the last 4 (which will be '.pdf') but you will need to adjust this depending on your filepath
x = file[20:-4]
# You may need to replace dashes or spaces with '_' or you may not need this at all
x = x.replace('-', '_')
# Use exec to set the dataframe name (really the reference) so each file you load will have its own df
exec(x '=df')
# Not necessary but might be helpful until code is optimal
print(x, df.shape)
}
And now, you will have a dataframe for each file in your directory. You can then map and transform them, output each one to a csv, or even use pandas concat to stack them all together and output one file.
CodePudding user response:
You could also try camelot.
It would look something like
cam = camelot.read(file=file_path, flavor='lattice') # (you might need to tweak some additional params, which I am happy to help you with
tables = cam.tables
# let's just assume camelot extracted 1 table
df = tables[0].df
# let's assume that the df looks as expected
column_you_want = list(df['column_title'])