i have a data frame like so;
mydf=data.frame(Authors=c("A","B","C"), ID=c("1","2","3"), Adresses=c("[XYZ, DEF] Ege Univ, Izmir, Turkey","[Vil, Beat; Fern, Alm; Pro-Pas, Ram; Fevfz, Jes; Saur, Mari] INIA CSIC, Dept Genet Anim, Madrid, Spain; [Penza, Carna; Housen, Rosie] Univ Edigh, Roxbn Inst, Edinburgh, Scotland","[Zeek, Umt] Kastamonu Univ, Kast, Turkey; [Kalu, Sear] Ege Univ, Fac Engn, Izmir, Turkey"))
it seems like this:

i want to split it according to pattern in Adresses column like this:
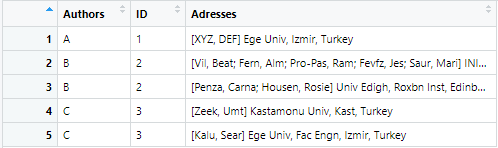
Here the pattern is something like this: [ ] ; But the last record of the cell (or if the cell has only one record ) doesn't have a semicolon as you can see from the first picture.
i tried with tidyr, dplyr, regex in r and also this strsplit(as.character(mydf[,3]), "[[(.*)]](.*);") pattern but it didn't work. Any help will be appreciated.
CodePudding user response:
You could use the ; (?=\\[)-regex, looking for a semi-colon and a space before a bracket.
E.g. with tidyr:
library(tidyr)
mydf |>
separate_rows(Adresses, sep = "; (?=\\[)")
Output:
# A tibble: 5 × 3
Authors ID Adresses
<chr> <chr> <chr>
1 A 1 [XYZ, DEF] Ege Univ, Izmir, Turkey
2 B 2 [Vil, Beat; Fern, Alm; Pro-Pas, Ram; Fevfz, Jes; Saur, Mari] INIA CSIC, Dept Genet Anim, Madrid, Spain
3 B 2 [Penza, Carna; Housen, Rosie] Univ Edigh, Roxbn Inst, Edinburgh, Scotland
4 C 3 [Zeek, Umt] Kastamonu Univ, Kast, Turkey
5 C 3 [Kalu, Sear] Ege Univ, Fac Engn, Izmir, Turkey
CodePudding user response:
You could use separate_rows() and set the separator as ';\\s*(?=\\[)':
library(tidyr)
mydf %>%
separate_rows(Adresses, sep = ';\\s*(?=\\[)')
# # A tibble: 5 × 3
# Authors ID Adresses
# <chr> <chr> <chr>
# 1 A 1 [XYZ, DEF] Ege Univ, Izmir, Turkey
# 2 B 2 [Vil, Beat; Fern, Alm; Pro-Pas, Ram; Fevfz, Jes; Saur, Mari] INIA…
# 3 B 2 [Penza, Carna; Housen, Rosie] Univ Edigh, Roxbn Inst, Edinburgh, …
# 4 C 3 [Zeek, Umt] Kastamonu Univ, Kast, Turkey
# 5 C 3 [Kalu, Sear] Ege Univ, Fac Engn, Izmir, Turkey
CodePudding user response:
In base R, we can split the column into a list of vectors and then replicate the rows of the data based on the lengths of the list and update the 'Adresses' by unlisting the list
lst1 <- strsplit(mydf$Adresses, ";\\s*(?=\\[)", perl = TRUE)
mydf2 <- transform(mydf[rep(seq_len(nrow(mydf)), lengths(lst1)),],
Adresses = unlist(lst1))
row.names(mydf2) <- NULL
-output
> mydf2
Authors ID Adresses
1 A 1 [XYZ, DEF] Ege Univ, Izmir, Turkey
2 B 2 [Vil, Beat; Fern, Alm; Pro-Pas, Ram; Fevfz, Jes; Saur, Mari] INIA CSIC, Dept Genet Anim, Madrid, Spain
3 B 2 [Penza, Carna; Housen, Rosie] Univ Edigh, Roxbn Inst, Edinburgh, Scotland
4 C 3 [Zeek, Umt] Kastamonu Univ, Kast, Turkey
5 C 3 [Kalu, Sear] Ege Univ, Fac Engn, Izmir, Turkey