I'm fairly new to R
I'm trying to create a Histogram of Diversity Index in my dataframe of counties, specifically the top 10 most populated counties
For instance, here's my dataframe ordered by most populated counties:
My code to get a histogram of all counties:
hist(race_counties$DiversityIndex, main = "Diversity Index of NY, NJ, and CT", las = 1, xlab = "Chance that any 2 people are from different ethnic groups (%)",
col = "blue",
density = 50,
angle = 0,
border = "black")
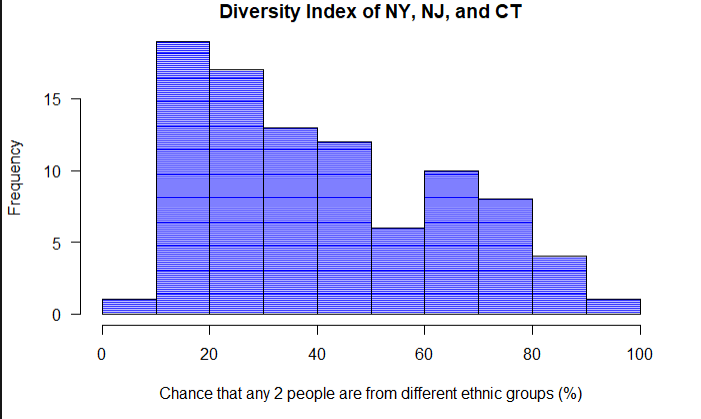
But I can't figure out how to make a histogram specifically of only these top 10
I've made this list as well trying to insert it into various parts of the code above but I can't figure out how to extract only these rows
top10 <- cbind("Kings County, New York",
"Queens County, New York",
"New York County, New York",
"Suffolk County, New York",
"Bronx County, New York",
"Nassau County, New York",
"Westchester County, New York",
"Fairfield County, New York",
"Bergen County, New York",
"Erie County, New York")
CodePudding user response:
You can use hist on race_counties$DiversityIndex[race_counties$NAME %in% top10].
The key is the use of %in%. You can read ?match for documentation of this operator.
There are a few previous questions on making a histogram on a subset of data. But I did not find one that features the combination of hist and %in%. So I answered this. But will be happy to delete it when someone does find a good dupe target.