Need your suggestion, I have below table generated dynamically based on monthly data.
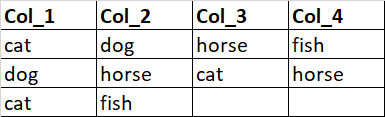
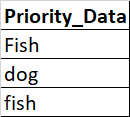
Need to compare each row across column and create a new data frame based on priority set as Fish > dog > horse > cat such that the sample output looks like,
df <- data.frame(Col_1 = c('cat', 'dog', 'cat'),
Col_2 = c('dog', 'horse', 'fish'),
Col_3 = c('horse', 'cat', NA),
Col_4 = c('fish', 'horse', NA))
CodePudding user response:
You can make your data into a long dataset with row numbers. Then you can arrange it as per your preference after grouping based on the row numbers. Then you can use slice to get the desired data frame.
library(tidyverse)
tribble(~col1, ~col2, ~col3, ~col4,
"cat", "dog", "horse", "fish",
"dog", "horse", "cat", "horse",
"cat", "fish", "NA", "NA") -> df
df %>%
mutate(rn = row_number()) %>%
pivot_longer(-rn) %>%
drop_na() %>%
group_by(rn) %>%
arrange(match(value, c("fish", "dog", "horse", "cat")), .by_group = T) %>%
slice(1) %>%
ungroup() %>%
select(value)
# A tibble: 3 × 1
value
<chr>
1 fish
2 dog
3 fish
CodePudding user response:
Throwing my solution to the ring
library(dplyr)
df %>%
rowwise() %>%
mutate(
priority = intersect(c('fish', 'dog', 'horse', 'cat'), c(X1, X2, X3, X4))[1]
) %>%
ungroup()
#> # A tibble: 3 × 5
#> X1 X2 X3 X4 priority
#> <chr> <chr> <chr> <chr> <chr>
#> 1 cat dog horse fish fish
#> 2 dog horse cat horse dog
#> 3 fish fish <NA> <NA> fish
Created on 2022-07-27 by the reprex package (v2.0.1)
Convert the desired rows to vectors, and then take the first item from the intersect of the priority vector.
If you only want the new column change mutate to transmute (or add ,.keep = 'none' to the mutate)
CodePudding user response:
You could define a custom order for character strings by ordered(...) or factor(..., ordered = TRUE). In this way you could use sort, min/max etc. to compare their priorities.
do.call(pmax,
c(lapply(df, ordered, levels = c('cat', 'horse', 'dog', 'fish')), na.rm = TRUE)
)
# [1] fish dog fish
# Levels: cat < horse < dog < fish
Data
df <- data.frame(Col_1 = c('cat', 'dog', 'cat'),
Col_2 = c('dog', 'horse', 'fish'),
Col_3 = c('horse', 'cat', NA),
Col_4 = c('fish', 'horse', NA))
CodePudding user response:
Another approach with base R with match and max.col:
prior_vec <- c('cat', 'horse', 'dog', 'fish')
s <- sapply(df, match, table = prior_vec, nomatch = 0)
df[cbind(1:nrow(df), max.col(s))]
which gives:
# [1] "fish" "dog" "fish"