I am trying to handle the following dataframe.
import pandas as pd
import numpy as np
df = pd.DataFrame({'ID':[1,1,2,2,2,3,3,3,3],
'sum':[1,1,1,2,3,1,4,4,4],
'flg':[1,np.nan, 1, np.nan, np.nan, 1, 1, np.nan, np.nan],
'year':[2018, 2019, 2018, 2019, 2020, 2018, 2019, 2020, 2021]})
df['diff'] = df.groupby('ID')['sum'].apply(lambda x: x - x.iloc[-1])
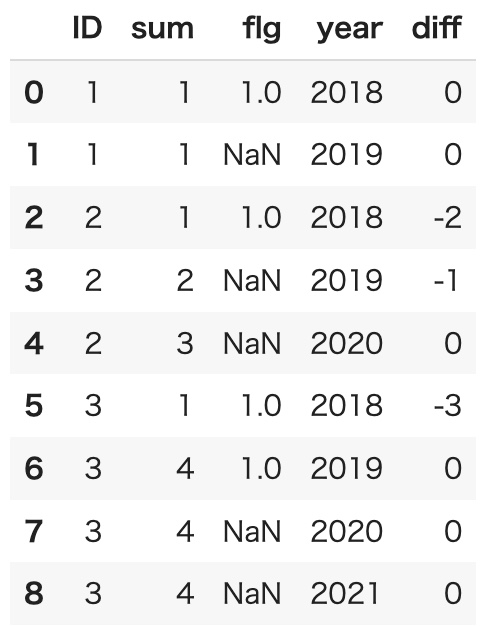
The 'diff' is the difference from the 'sum' of the final year of each ID.
So, I tried the following code to remove the final year row used for comparison.
comp = df.groupby('ID').last().reset_index()
col = list(df.columns)
fin =pd.merge(df, comp, on=col, how='outer', indicator=True).query(f'_merge != "both"')
But here is where the problem arises.
The contents of 'comp' are as follows.
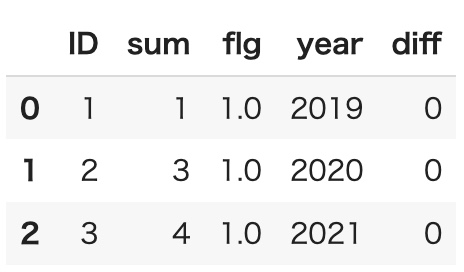
The 'comp' I originally wanted to get is below.
ID sum flg year diff
1 1 Nan 2019 0
2 3 Nan 2020 0
3 4 Nan 2021 0
Why is the Nan in 'flg' being complemented to 1 by itself? Please let me know if there is a better way to do this.
CodePudding user response:
IIUC, use head(-1):
g = df.groupby('ID')
out = g.head(-1).assign(diff=g['sum'].apply(lambda x: x - x.iloc[-1]))
output:
ID sum flg year diff
0 1 1 1.0 2018 0
2 2 1 1.0 2018 -2
3 2 2 NaN 2019 -1
5 3 1 1.0 2018 -3
6 3 4 1.0 2019 0
7 3 4 NaN 2020 0
Variant:
g = df.groupby('ID')
out = g.head(-1).assign(diff=lambda d: d['sum'].sub(g['sum'].transform('last')))
CodePudding user response:
You can use the method duplicated:
df['diff'] = df['sum'] - df.groupby('ID')['sum'].transform('last')
df = df[df.duplicated('ID', keep='last')]
Output:
ID sum flg year diff
0 1 1 1.0 2018 0
2 2 1 1.0 2018 -2
3 2 2 NaN 2019 -1
5 3 1 1.0 2018 -3
6 3 4 1.0 2019 0
7 3 4 NaN 2020 0
CodePudding user response:
For a fix to your problem see other answers. Concerning your question "Why is the Nan in 'flg' being complemented to 1 by itself?":
pandas.core.groupby.GroupBy.last does not just pick the last row in each group, as one might assume, but finds the last non-nan value in each individual column within the group. In the Pandas source code this is evident from the function
def last(x: Series):
"""Helper function for last item that isn't NA."""
arr = x.array[notna(x.array)]
if not len(arr):
return np.nan
return arr[-1]
which is applied to each column. I think the Pandas API reference could be a bit more explicit there (rather than "Compute last of group values.").
CodePudding user response:
replace last with tail(1) and drop the added index column:
comp = df.groupby('ID').tail(1).reset_index().drop('index', axis=1)
OUTPUT
ID sum flg year diff
0 1 1 NaN 2019 0
1 2 3 NaN 2020 0
2 3 4 NaN 2021 0