In the end, both revisions and references are pointers to Git objects so what is the point having both?
CodePudding user response:
... and that's it (?).
And that's it... almost.
Git uses the filesystem as its database. References are stored in one of two places. .git/refs and .git/packed-refs.
.git/refs/ contains a file for each reference. For example, the main branch is in .git/refs/heads/main. The tag v1.2.3 is in .git/refs/tags/v1.2.3. The file contains the SHA of the commit it references. When you ask for main, git searches these directories and when it finds a filename that matches it reads the SHA from the file. Simple. This is why you can also refer to the main branch as main, heads/main, and refs/heads/main; they're just relative file paths to search.
Searching a directory tree gets unwieldy if there are many references and doesn't scale, especially on network drives. So git will occasionally "pack" these references into a single file, .git/packed-refs. This is a simple file with one line for each reference and the format <sha> <ref>. Git opens the file, reads until it finds a matching reference, and uses its sha.
Such a small and frequently referenced file will likely remain in the operating system's cache making subsequent reads very fast. New references go into .git/refs/ to avoid having to rewrite the whole packfile every time; Git will write a new packfile periodically.
It's a very fast, very elegant, and very portable solution to use the filesystem as its database rather than something like SQLite or a binary file format.
You can read more about 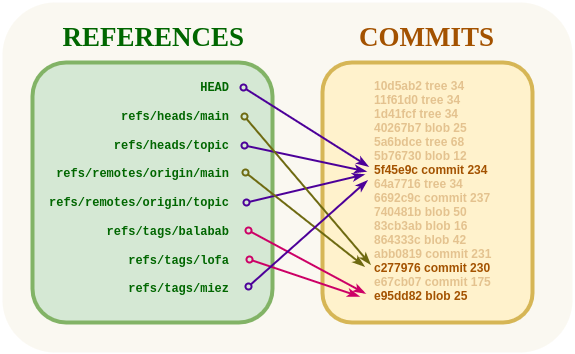
Git revisions
A Git revision is a string of characters conforming to a special notation syntax - or "revision query system"4 - that are used to unambiguously select one or more Git objects2.
[4]: Much like how database systems (e.g., PostgreSQL) use a query language (e.g., SQL), but in this case Git is the database system and the revision syntax is the query language. The analogy seems apt to the extent to revisions being able to refer to a range of Git objects too.
The connection
Git references are simply labels for specific Git objects, but there are plenty of times when one would like to carry out operations on other objects as well. The only way to do it without revisions is to manually find them and then list all the SHA-1 hashes of the Git objects involved.
The revision notation is a query system to reach any Git object (or a range of them) in a repo by traversing the directed acyclic graph or DAG.
The fundamental building blocks of relative5 revision queries are
extended SHA-1 syntax (e.g.,
<sha1>, e.g.dae86e1950b1277e545cee180551750029cfe735,dae86e)Git references (which ultimately resolve to
<sha1>)
where references serve as starting points to begin traversing the graph.
[5]: The use of "relative" is important here, because there are also :/<text> and :\[<n>:\]<path> that require no anchor.
At least, every notation from the gitrevisions docs boil down to the above conclusion:
-
<describeOutput>, e.g.v1.7.4.2-679-g3bee7fbgit describe"finds the most recent tag that is reachable from a commit". Tags are Git references, andgit describealready has its own revision-esque notation for its results. -
[<branchname>]@{upstream}, e.g.master@{upstream},@{u}Branch names are Git references, and the rest is the revision query notation. -
<rev>^{<type>}, e.g.v0.99.8^{commit}Where<rev>means to "dereference the object at recursively", so in the end we'll get to a tag or<sha1>.