Suppose I have the following df:
df = pd.DataFrame({"call 1": ['debit card','bond',np.nan],
"call 2": ['credit card','mortgage','spending limit'],
"call 3":['payment limit',np.nan,np.nan]})
which gives:
call 1 call 2 call 3
0 debit card credit card payment limit
1 bond mortgage NaN
2 NaN spending limit NaN
I want to make a bubble chart such that each bubble presents the columns. So in the example above I want to plot 3 bubbles representing call 1, call 2 and call 3. On each bubble I want to present the values as well, for instance the bubble for call 1 includes the values debit card and bond as its legend. Finally the size of each bubble would be equal to the length of non-null values of each column, I've calculated that as:
size = []
for column in df:
size.append(df[column].notna().sum())
#output: [2,3,1]
I wonder how one would make such bubble chart? note that this type of chart has no x or y value. So I'm not sure how to use matplotlib / seaborn /etc
the outcome should look like the following:
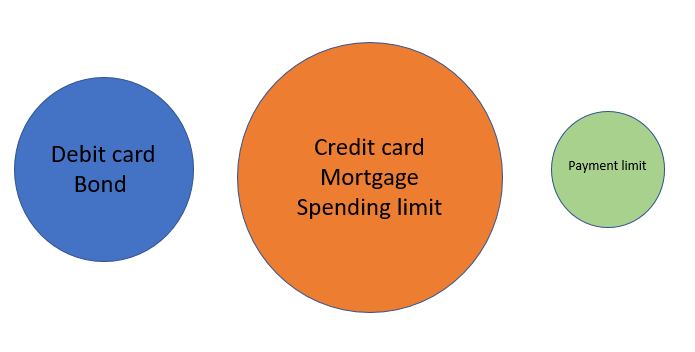
My very primitive way of doing this is as follow (using brute force):
test = pd.DataFrame({'calls':['call 1','call 1','call 2', 'call 2', 'call 2', 'call 3'],
'size':[2,2,3,3,3,1],
'y':[1,1,1,1,1,1],
'x':[1,1.1,2,2.1,2.2,3],
'vals': ['debit card', 'bond', 'credit card', 'mortgage', 'spending limit', 'payment limit']})
fig = px.scatter(test, x="x", y="y",
size="size", color="calls",
hover_name="calls", hover_data=["vals"], log_x=False, size_max=60)
fig.show()
where each point is a bubble - and I had to enforce the locations so I can see the labels. Surely, my method is not very useful.
CodePudding user response:
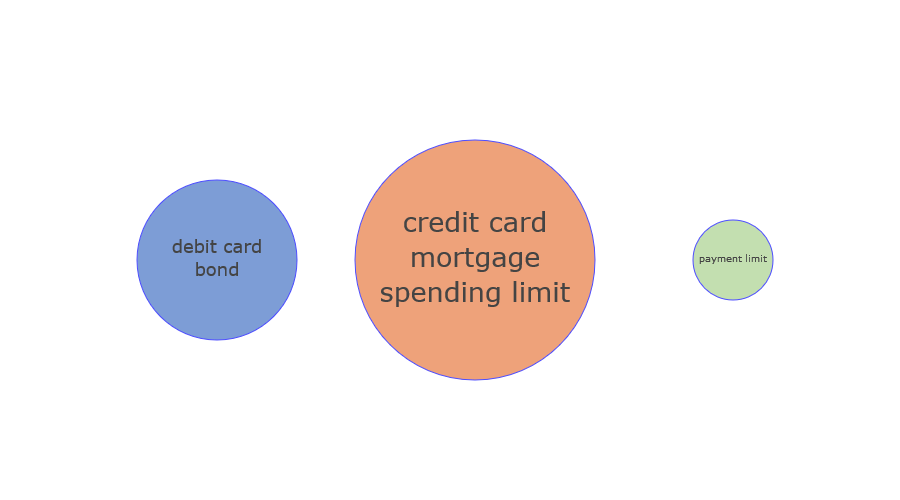
Making a graph look like an indicator involves trial and error. We assume we are using your data, grouping it and listing the values for annotation. First, draw a circle in scatterplot marker mode. The size is multiplied by a constant based on the size of the data column. Next, the annotations are also placed in the center using the text mode of the scatterplot, merging the listed strings with line breaks. The font size is also varied using the size column of the data. Finally, the graph background and axis scales are disabled.
import pandas as pd
import numpy as np
import plotly.graph_objects as go
df = pd.DataFrame({"call 1": ['debit card','bond',np.nan],
"call 2": ['credit card','mortgage','spending limit'],
"call 3":['payment limit',np.nan,np.nan]})
df = df.melt( value_vars=['call 1','call 2', 'call 3'],var_name='calls',value_name='vals')
df.dropna(inplace=True)
dfs = df.copy()
df = df.groupby('calls')['vals'].agg(list).to_frame()
df['size'] = dfs.groupby('calls')['vals'].size()
df.reset_index(inplace=True)
df
calls vals size
0 call 1 [debit card, bond] 2
1 call 2 [credit card, mortgage, spending limit] 3
2 call 3 [payment limit] 1
fig = go.Figure()
fig.add_trace(go.Scatter(mode='markers',
x=df['calls'],
y=[1,1,1],
marker=dict(
size=df['size']*80,
color=['rgb(68, 114, 196)','rgb(230, 122, 65)','rgb(169, 209, 142)'],
line_color='blue'
)))
fig.add_trace(go.Scatter(mode='text',
x=df['calls'],
y=[1,1,1],
text=['<br>'.join(x) for x in df['vals'].tolist()],
textposition='middle center',
textfont_size=[18*(s*0.5) for s in df['size']]
))
fig.update_layout(autosize=False,
height=500,
width=900,
template='none',
showlegend=False,
)
fig.update_yaxes(visible=False, showticklabels=False)
fig.update_xaxes(visible=False, showticklabels=False)
fig.show()