I am new to the selenium framework and I must say it is an awesome library. I am basically trying to get all links from a webpage that has a particular id "pagination", and isolate them from links that don't have such id, reasons because I want to go through all the pages in this link.
for j in browser.find_elements(By.CSS_SELECTOR, "div#col-content > div.main-menu2.main-menu-gray strong a[href]"):
print(j.get_property('href')))
The code above gets all the links with and without pagination.
example links with pagination.
https://www.oddsportal.com/soccer/africa/africa-cup-of-nations-2015/results/
https://www.oddsportal.com/soccer/england/premier-league-2020-2021/results/
https://www.oddsportal.com/soccer/africa/africa-cup-of-nations-2021/results/
https://www.oddsportal.com/soccer/africa/africa-cup-of-nations-2019/results/
example links without pagination.
https://www.oddsportal.com/soccer/africa/africa-cup-of-nations/results/
In my code, I try to find if the given ID exists on the page, pagination = browser.find_element(By.ID, "pagination") but I stumble on an error, I understand the reason for the error, and it is coming from the fact that the ID "pagination" does not exist on some of the links.
no such element: Unable to locate element: {"method":"css selector","selector":"[id="pagination"]"}
I changed the above code to pagination = browser.find_elements(By.ID, "pagination"), which returns links with and without pagination. so my question is how can I get links that has a particular id from list of links.
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.by import By
import time
import tqdm
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
#define our URL
url = 'https://oddsportal.com/results/'
path = r'C:\Users\Glodaris\OneDrive\Desktop\Repo\Scraper\chromedriver.exe'
options = ChromeOptions()
options.headless = True
# options=options
browser = Chrome(executable_path=path, options=options)
browser.get(url)
title = browser.title
print('Title', title)
links = []
for i in browser.find_elements(By.CSS_SELECTOR, "div#archive-tables tbody tr[xsid='1'] td a[href]"):
links.append(i.get_property('href'))
arr = []
condition = True
while condition:
for link in (links):
second_link = browser.get(link)
for j in browser.find_elements(By.CSS_SELECTOR, "div#col-content > div.main-menu2.main-menu-gray strong a[href]"):
browser.implicitly_wait(2)
pagination = browser.find_element(By.ID, "pagination")
if pagination:
print(pagination.get_property('href')))
else:
print(j.get_property('href')))
try:
browser.find_elements("xpath", "//*[@id='pagination']/a[6]")
except:
condition = False
CodePudding user response:
As you are using Selenium, you are able to actually click on the pagination's forward button to navigate through pages. The following example will test for cookie button, will scrape the data from the main table as a dataframe, will check if there is pagination, and if not, will stop there. If there is pagination, will navigate to next page, get the data from the table, navigate to the next page and so on, until the table data from the page is identical with table data from previous page, and then will stop. It is able to handle an n number of pages. The setup in the code below is for linux, what you need to pay attention to is the imports part, as well as the part after you define the browser/driver.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time as t
import pandas as pd
chrome_options = Options()
chrome_options.add_argument("--no-sandbox")
webdriver_service = Service("chromedriver/chromedriver") ## path to where you saved chromedriver binary
browser = webdriver.Chrome(service=webdriver_service, options=chrome_options)
# url='https://www.oddsportal.com/soccer/africa/africa-cup-of-nations/results/'
url = 'https://www.oddsportal.com/soccer/africa/africa-cup-of-nations-2021/results/'
browser.get(url)
try:
WebDriverWait(browser, 10).until(EC.element_to_be_clickable((By.ID, "onetrust-reject-all-handler"))).click()
except Exception as e:
print('no cookie button!')
games_table = WebDriverWait(browser, 20).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "table[id='tournamentTable']")))
try:
initial_games_table_data = games_table.get_attribute('outerHTML')
dfs = pd.read_html(initial_games_table_data)
print(dfs[0])
except Exception as e:
print(e, 'Unfortunately, no matches can be displayed because there are no odds available from your selected bookmakers.')
while True:
browser.execute_script("window.scrollTo(0,document.body.scrollHeight);")
t.sleep(1)
try:
forward_button = WebDriverWait(browser, 20).until(EC.element_to_be_clickable((By.XPATH, "//div[@id='pagination']//span[text()='»']")))
forward_button.click()
except Exception as e:
print(e, 'no pagination, stopping here')
break
games_table = WebDriverWait(browser, 20).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "table[id='tournamentTable']")))
dfs = pd.read_html(games_table.get_attribute('outerHTML'))
games_table_data = games_table.get_attribute('outerHTML')
if games_table_data == initial_games_table_data:
print('this is the last page')
break
print(dfs[0])
initial_games_table_data = games_table_data
print('went to next page')
t.sleep(3)
CodePudding user response:
You are seeing the error message...
no such element: Unable to locate element: {"method":"css selector","selector":"[id="pagination"]"}
...as all the pages doesn't contain the element:
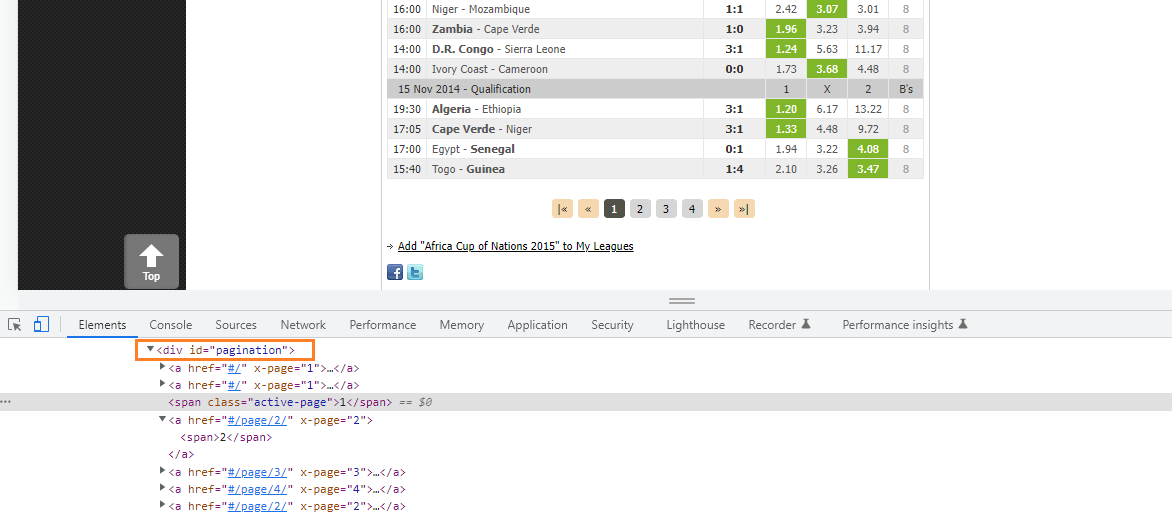
<div id="pagination">
<a ...>
<a ...>
<a ...>
</div>
Solution
In these cases your best approach would be to wrapup the code block with in a try-except{} block as follows:
for j in browser.find_elements(By.CSS_SELECTOR, "div#col-content > div.main-menu2.main-menu-gray strong a[href]"):
try:
print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.ID, "pagination"))).get_property('href'))
except:
continue
Note : You have to add the following imports :
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
Update
A couple of things to note.
- The
(By.ID, "pagination")element doesn't have ahrefattribute but the several decendants have. So you may find conflicting results.
- As you are using WebDriverWait remember to remove all the instances of
implicitly_wait()as mixing implicit and explicit waits can cause unpredictable wait times. For example setting an implicit wait of 10 seconds and an explicit wait of 15 seconds, could cause a timeout to occur after 20 seconds.