I have this dataframe:
final_df = [['Name', 'Gender', 'Amount', 'amount2', 'Amount3', 'Percent total of gender'], ['Mike', 'Male', 50, nan, 0, 0.20833333333333334], ['Nancy', 'Female', 30, nan, 0, 0.42857142857142855], ['Bob', 'Male', 100, nan, 0, 0.4166666666666667], ['Terrance', 'Male', 30, nan, 0, 0.125], ['Sara', 'Female', 40, nan, 0, 0.5714285714285714], ['Myo', 'Male', 60, nan, 0, 0.25]]
Name Gender Rate Hours Amount3
Mike Male 20 30 3,000.00
Nancy Female 10 50 1,500.00
Bob Male 30 40 6,000.00
Terrance Male 40 60 12,000.00
Sara Female 35 32 3,360.00
Myo Male 15 80 6,000.00
I have this code for the simple average:
final_df['Weighted Average'] = final_df.groupby('Gender')['Amount3'].transform(lambda x: x/x.sum() if x.sum() > 0 else 0 )
I'm trying to add a weighted average column that will take (Rate * Hours) * (Amount3/groupby.sum())
My desired output would be:
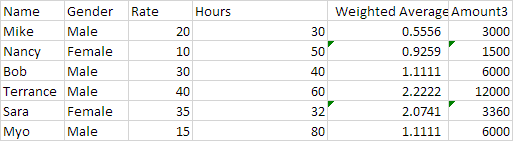
Any ideas?
CodePudding user response:
Given your numbers, it looks like the expected computation is:
df['Weighted Average'] = (
df['Amount3']/(df['Rate']*df['Hours'])
*df.groupby('Gender')['Amount3'].transform(lambda x: x/x.sum() if x.sum() > 0 else 0 )
)
which, somehow is quite weird as this is equivalent to something proportional to the square of Amount3:
df['Weighted Average'] = (
df['Amount3']**2/(df['Rate']*df['Hours'])
/df.groupby('Gender')['Amount3'].transform('sum').fillna(0)
)
output:
Name Gender Rate Hours Amount3 Weighted Average
0 Mike Male 20 30 3000.0 0.555556
1 Nancy Female 10 50 1500.0 0.925926
2 Bob Male 30 40 6000.0 1.111111
3 Terrance Male 40 60 12000.0 2.222222
4 Sara Female 35 32 3360.0 2.074074
5 Myo Male 15 80 6000.0 1.111111
CodePudding user response:
If I understand correctly you need something like:
df['Weighted Average'] = (df.Rate * df.Hours) * (df.Amount3 / df.Gender.map(df.groupby('Gender').Amount3.sum()))