Currently I have many rows in one column similar to the string below. On python I have run the code to remove
, <a, href=, and the url itself using this code
df["text"] = df["text"].str.replace(r'\s*https?://\S (\s |$)', ' ').str.strip()
df["text"] = df["text"].str.replace(r'\s*href=//\S (\s |$)', ' ').str.strip()
However, the output continues to remain the same. Please advise.
<p>On 4 May 2019, <a href="https://www.ft.com/content/26b6d24e-6d77-11e9-a9a5-351eeaef6d84">The Financial Times</a> (FT) reported that Huawei is planning to build a '400-person chip research and development factory' outside Cambridge. Planned to be operational by 2021, the factory will include an R&D centre and will be built on a 550-acre site reportedly purchased by Huawei in 2018 for £37.5 million. A Huawei spokesperson quoted in the FT article cited Huawei's long-term collaboration with Cambridge University, which includes a five-year, £25 million research partnership with BT, which launched a joint research group at the University of Cambridge. Read more about that partnership on this <a href="https://chinatechmap.aspi.org.au/#/map/marker-1024">map.</a></p>
<p>In 2020 it was reported that the Huawei research and development center <a href="https://archive.ph/wip/OrAd3">received approval by a local council</a> despite the nation’s ongoing security concerns around the Chinese company.</p>
<p>Chinese state media later <a href="https://web.archive.org/web/20190505143025/https://www.chinadaily.com.cn/a/201905/05/WS5ccecddfa3104842260b9df9.html">reported that</a> Huawei's expansion in Cambridge 'is part of a five-year, £3 billion investment plan for the UK that [Huawei] announced alongside [then] British Prime Minister Theresa May' in February 2018.</p>
CodePudding user response:
You can use the following regex pattern instead:
<a href=(.*?)">
I successfully tested this using your test string on 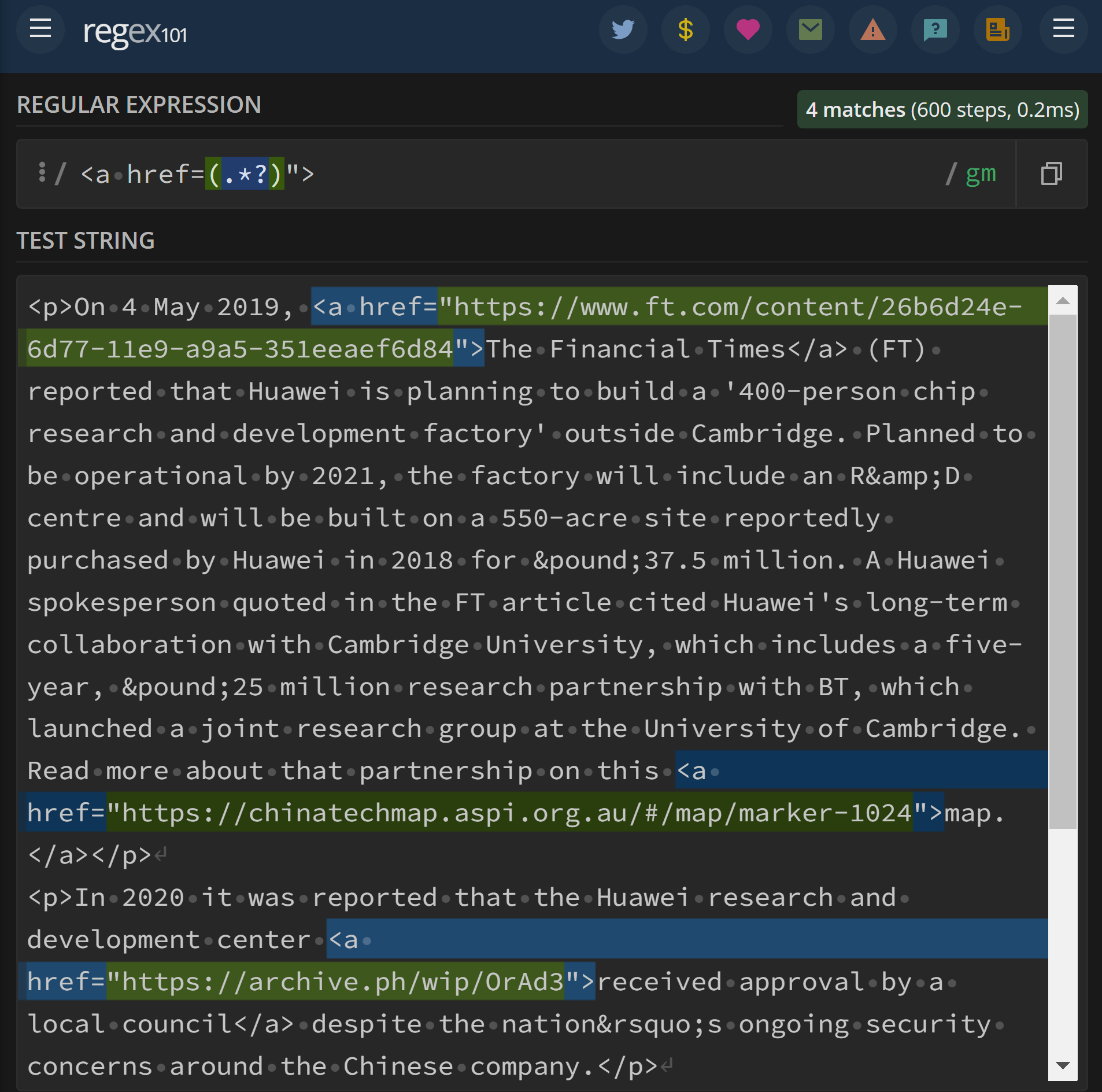
Full code:
import re
df["text"] = df["text"].str.replace(r'<a href=(.*?)">', "").str.strip()
CodePudding user response:
I don't think your regex is quite right. Try:
df["text"] = df["text"].str.replace(r'<a href=\".*?\">', ' ').str.strip()
df["text"] = df["text"].str.replace(r'</a>', ' ').str.strip()
CodePudding user response:
IIUC you want to replace the following html tags:
<p>, <a, href=, and the url
Code
df['text'] = df.text.replace(regex = {r'<p>': ' ', r'</p>': '', r'<a.*?\/a>': ' '})
Explanation
Regex dictionary does the following substitutions
- <p> replaced by ' '
- <a href = .../a> replaced by ' '
- </p> replaced by ''
Example
Create Data
s = '''<p>On 4 May 2019, <a href="https://www.ft.com/content/26b6d24e-6d77-11e9-a9a5-351eeaef6d84">The Financial Times</a> (FT) reported that Huawei is planning to build a '400-person chip research and development factory' outside Cambridge. Planned to be operational by 2021, the factory will include an R&D centre and will be built on a 550-acre site reportedly purchased by Huawei in 2018 for £37.5 million. A Huawei spokesperson quoted in the FT article cited Huawei's long-term collaboration with Cambridge University, which includes a five-year, £25 million research partnership with BT, which launched a joint research group at the University of Cambridge. Read more about that partnership on this <a href="https://chinatechmap.aspi.org.au/#/map/marker-1024">map.</a></p>
<p>In 2020 it was reported that the Huawei research and development center <a href="https://archive.ph/wip/OrAd3">received approval by a local council</a> despite the nation’s ongoing security concerns around the Chinese company.</p>
<p>Chinese state media later <a href="https://web.archive.org/web/20190505143025/https://www.chinadaily.com.cn/a/201905/05/WS5ccecddfa3104842260b9df9.html">reported that</a> Huawei's expansion in Cambridge 'is part of a five-year, £3 billion investment plan for the UK that [Huawei] announced alongside [then] British Prime Minister Theresa May' in February 2018.</p>'''
data = {'text':s.split('\n')}
df = pd.DataFrame(data)
print(df.text[0]) # show first row pre-replacement
# Perform replacements
df['text'] = df.text.replace(regex = {r'<p>': ' ', r'</p>': '', r'<a.*?\/a>': ' '})
print(df.text[0]) # show first row post replacement
Output
The first row only
Before replacement
On 4 May 2019, The Financial Times (FT) reported that Huawei is planning to build a '400-person chip research and development factory' outside Cambridge. Planned to be operational by 2021, the factory will include an R&D centre and will be built on a 550-acre site reportedly purchased by Huawei in 2018 for £37.5 million. A Huawei spokesperson quoted in the FT article cited Huawei's long-term collaboration with Cambridge University, which includes a five-year, £25 million research partnership with BT, which launched a joint research group at the University of Cambridge. Read more about that partnership on this map.
Post Replacement
On 4 May 2019, (FT) reported that Huawei is planning to build a '400-person chip research and development factory' outside Cambridge. Planned to be operational by 2021, the factory will include an R&D centre and will be built on a 550-acre site reportedly purchased by Huawei in 2018 for £37.5 million. A Huawei spokesperson quoted in the FT article cited Huawei's long-term collaboration with Cambridge University, which includes a five-year, £25 million research partnership with BT, which launched a joint research group at the University of Cambridge. Read more about that partnership on this