np.random.seed(2022) # added to make the data the same each time
cols = pd.MultiIndex.from_arrays([['A','A' ,'B','B'], ['min','max','min','max']])
df = pd.DataFrame(np.random.rand(3,4),columns=cols)
df.index.name = 'item'
A B
min max min max
item
0 0.009359 0.499058 0.113384 0.049974
1 0.685408 0.486988 0.897657 0.647452
2 0.896963 0.721135 0.831353 0.827568
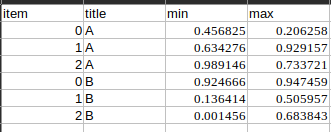
There are two column headers and while working with csv, I get a blank column name for every other column on unmerging.
I want result that looks like this. How can I do it? I tried to use pivot table but couldn't do it.
CodePudding user response:
Try:
df = (
df.stack(level=0)
.reset_index()
.rename(columns={"level_1": "title"})
.sort_values(by=["title", "item"])
)
print(df)
Prints:
item title max min
0 0 A 0.762221 0.737758
2 1 A 0.930523 0.275314
4 2 A 0.746246 0.123621
1 0 B 0.044137 0.264969
3 1 B 0.577637 0.699877
5 2 B 0.601034 0.706978
Then to CSV:
df.to_csv('out.csv', index=False)