I have a dataframe like this:
id <- c(rep(1234, 6), rep(5678, 10), rep(9101, 5))
date <- seq(as.Date("2020-01-01"), as.Date("2020-01-21"), by = "days")
mode <- c(1, 1, 1, 2, 2, 2, 1, 1, 2, 1, 1, 1, 2, 2, 2, 2, 1, 1, 2, 2, 2)
df <- data.frame(id, date, mode)
I want to group by id and extract all of the rows which have at least three consecutive 2s in the mode column IF those 2s are preceded by at least three consecutive 1s.
My expected output for dataframe above would be
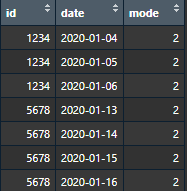
Thank you.
CodePudding user response:
This method keeps rows which have at least three consecutive 2's that follow at least three consecutive 1's.
library(dplyr)
df %>%
group_by(id, grp = data.table::rleid(mode)) %>%
semi_join(summarise(., mode = mode[1], n = n()) %>%
filter(mode == 2 & n >= 3 & lag(mode) == 1 & lag(n) >= 3),
by = c("id", "grp")) %>%
ungroup() %>%
select(-grp)
# # A tibble: 7 × 3
# id date mode
# <dbl> <date> <dbl>
# 1 1234 2020-01-04 2
# 2 1234 2020-01-05 2
# 3 1234 2020-01-06 2
# 4 5678 2020-01-13 2
# 5 5678 2020-01-14 2
# 6 5678 2020-01-15 2
# 7 5678 2020-01-16 2
CodePudding user response:
For this dataset:
library(dplyr)
df %>%
mutate(counter= cumsum(mode!=lag(mode, default=FALSE))) %>%
group_by(id, counter) %>%
filter(n() >= 3 & mode==2) %>%
ungroup() %>%
select(-counter)
id date mode
<dbl> <date> <dbl>
1 1234 2020-01-04 2
2 1234 2020-01-05 2
3 1234 2020-01-06 2
4 5678 2020-01-13 2
5 5678 2020-01-14 2
6 5678 2020-01-15 2
7 5678 2020-01-16 2
CodePudding user response:
Here is one option with rle
library(dplyr)
f1 <- function(x) {
rl <- rle(x)
any(rl$values == 2 & lag(rl$values) == 1 &
rl$lengths >= 3, na.rm = TRUE) & x == 2
}
df %>%
group_by(id) %>%
filter(f1(mode)) %>%
ungroup
# A tibble: 6 × 3
id date mode
<dbl> <date> <dbl>
1 1234 2020-01-04 2
2 1234 2020-01-05 2
3 1234 2020-01-06 2
4 9101 2020-01-19 2
5 9101 2020-01-20 2
6 9101 2020-01-21 2
CodePudding user response:
> r=rle(mode)
> l=length(r$values)
> v1=r$values;v2=c(NA,v1[-l])
> l1=r$lengths;l2=c(NA,l1[-l])
> pick=v1==2&v2==1&l1>=2&l2>=3
> df[rep(pick,r$lengths),]
id date mode
4 1234 2020-01-04 2
5 1234 2020-01-05 2
6 1234 2020-01-06 2
13 5678 2020-01-13 2
14 5678 2020-01-14 2
15 5678 2020-01-15 2
16 5678 2020-01-16 2
19 9101 2020-01-19 2
20 9101 2020-01-20 2
21 9101 2020-01-21 2