My final goal is to take each xml file and enter the raw format of the XML into Snowflake, and this is the result I have so far. For some reason though when i convert the list to a Dataframe, the dataframe is only take a couple items from the list for each file...and not the entire 5000 rows in the xml.
My list Data is grabbing all contents from multiple files, in the list you can see the following:
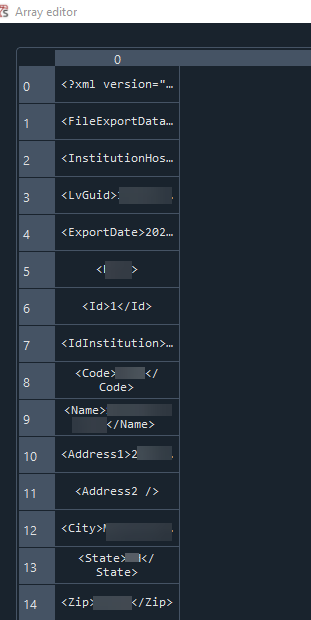
Each list item is genertating a numpy array and its splitting up the elements from the looks of it.
dated = datetime.today().strftime('%Y-%m-%d')
source_dir = r'C:\Users\jSmith\.spyder-py3\SampleXML'
table_name = 'LV_XML'
file_list = glob.glob(source_dir '/*.XML')
data = []
for file_path in file_list:
data.append(
np.genfromtxt(file_path,dtype='str',delimiter='|',encoding='utf-8')) #delimiter used to make sure it is not splitting based on spaces, might be the issue?
df = pd.DataFrame(list(zip(data)),
columns =['SRC_XML'])
df['SRC_XML']=df['SRC_XML'].astype(str)
df = df.replace(',','', regex=True)
df["TPR_AS_OF_DT"] = dated
The data frame has the following in each column:
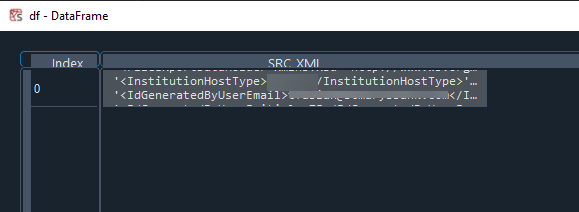

Solution via Dave, with a small tweak:
for file_path in file_list: with open(file_path,'r') as afile: content = '' for aline in afile: content = aline.replace('\n',' ') # changed to replace for my needs data.append(content)
This puts the data into a single string, and allows it to be ready to be inserted into the Snowflake table as 1 string...for future queries
CodePudding user response:
Perhaps replace the file reading with this:
for file_path in file_list:
with open(file_path,'r') as afile:
content = ''
for aline in afile:
content = aline.strip('\n')
data.append(content)