I am trying to mutate and lag the same column in R dplyr, per the reproducible code at the bottom of this post. That code doesn't give my what I'm looking for. What am I doing wrong?
Running the code gives me these incorrect results, where column nameCntMult is the one I'm trying to lag:
> dataFill
# A tibble: 6 x 4
Name Code nameCnt nameCntMult
<chr> <dbl> <int> <dbl>
1 R 0 1 1
2 R 0 2 2
3 T 0 1 1
4 R 0 3 3
5 N 1 1 NA
6 N 1 2 2
When I'm looking for these results, rendered in XLS:
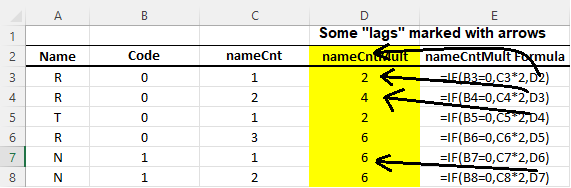
Reproducible code:
library(dplyr)
data <-
data.frame(
Name = c("R","R","T","R","N","N"),
Code = c(0,0,0,0,1,1)
)
dataFill <-data %>%
group_by(Name, Code) %>%
mutate(nameCnt = row_number())%>%
mutate(nameCntMult = nameCnt * 2) %>%
mutate(nameCntMult = ifelse(Code == 0, nameCnt, lag(nameCntMult))) %>%
ungroup()
dataFill
CodePudding user response:
Changing the order of mutates and ungroup would get you the answer you're looking for:
library(dplyr)
data <-
data.frame(
Name = c("R","R","T","R","N","N"),
Code = c(0,0,0,0,1,1)
)
dataFill <-data %>%
group_by(Name, Code) %>%
mutate(nameCnt = row_number())%>%
mutate(nameCntMult = nameCnt * 2) %>%
ungroup() %>%
mutate(nameCntMult = ifelse(Code == 0, nameCntMult, lag(nameCntMult))) %>%
mutate(nameCntMult = ifelse(Code == 0, nameCntMult, lag(nameCntMult)))
dataFill
#> # A tibble: 6 × 4
#> Name Code nameCnt nameCntMult
#> <chr> <dbl> <int> <dbl>
#> 1 R 0 1 2
#> 2 R 0 2 4
#> 3 T 0 1 2
#> 4 R 0 3 6
#> 5 N 1 1 6
#> 6 N 1 2 6
by also lagging the last 6 twice. When mutating before ungrouping the lag looks for the last value in that group, but cannot find it in your row 5 because it's the first of that group.
But this might not be the full answer you're looking for. Do you want nameCntMult to be the double of the last nameCnt value in a row where Code == 0?
Edit - fuller solution using only dplyr
Here's a way to do it across as many rows as needed:
data |>
group_by(Name, Code) |>
mutate(nameCnt = row_number()) |>
ungroup() |>
mutate(nameCntMult = ifelse(Code == 0, nameCnt * 2, NA)) |>
mutate(grp = cumsum(!is.na(nameCntMult))) |>
group_by(grp) |>
mutate(nameCntMult = max(nameCntMult, na.rm = TRUE)) |>
ungroup() |>
select(-grp)
#> # A tibble: 6 × 4
#> Name Code nameCnt nameCntMult
#> <chr> <dbl> <int> <dbl>
#> 1 R 0 1 2
#> 2 R 0 2 4
#> 3 T 0 1 2
#> 4 R 0 3 6
#> 5 N 1 1 6
#> 6 N 1 2 6
(works by first assigning NAs to rows with Code == 1, then grouping these with previous non-NA value with a temporary grp variable and replacing the max(nameCntMult) across these rows)
CodePudding user response:
This is a recursive computation dependent on 2 vectors, i.e. nameCnt and Code. In this case you could use accumulate2() from purrr.
library(dplyr)
library(purrr)
fun <- function(x, y, code) if(code == 0) y * 2 else x
data %>%
group_by(Name, Code) %>%
mutate(nameCnt = row_number()) %>%
ungroup() %>%
mutate(nameCntMult = accumulate2(nameCnt, Code, fun, .init = NA)[-1] %>% flatten_dbl)
# # A tibble: 6 × 4
# Name Code nameCnt nameCntMult
# <chr> <dbl> <int> <dbl>
# 1 R 0 1 2
# 2 R 0 2 4
# 3 T 0 1 2
# 4 R 0 3 6
# 5 N 1 1 6
# 6 N 1 2 6
There is also a base equivalent of accumulate2, i.e. Reduce().
... %>%
mutate(nameCntMult = Reduce(function(x, y) if(Code[y] == 0) nameCnt[y] * 2 else x,
1:n(), init = NA, accumulate = TRUE)[-1])