data frame :
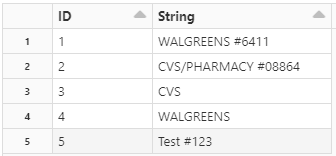
I need to truncate the String column value based on the # position. The result should be :

I am trying this code but it is throwing a TypeError :

Though I can achieve the desired result using SparkSql or by creating a function in Python, is there any way that it can be done in pyspark itself?
CodePudding user response:
Another way is to use locate within the substr function, but this can only be used with expr.
spark.sparkContext.parallelize([('WALGREENS #6411',), ('CVS/PHARMACY #08864',), ('CVS',)]).toDF(['acct']). \
withColumn('acct_name',
func.when(func.col('acct').like('%#%') == False, func.col('acct')).
otherwise(func.expr('substr(acct, 1, locate("#", acct)-2)'))
). \
show()
# ------------------- ------------
# | acct| acct_name|
# ------------------- ------------
# | WALGREENS #6411| WALGREENS|
# |CVS/PHARMACY #08864|CVS/PHARMACY|
# | CVS| CVS|
# ------------------- ------------
CodePudding user response:
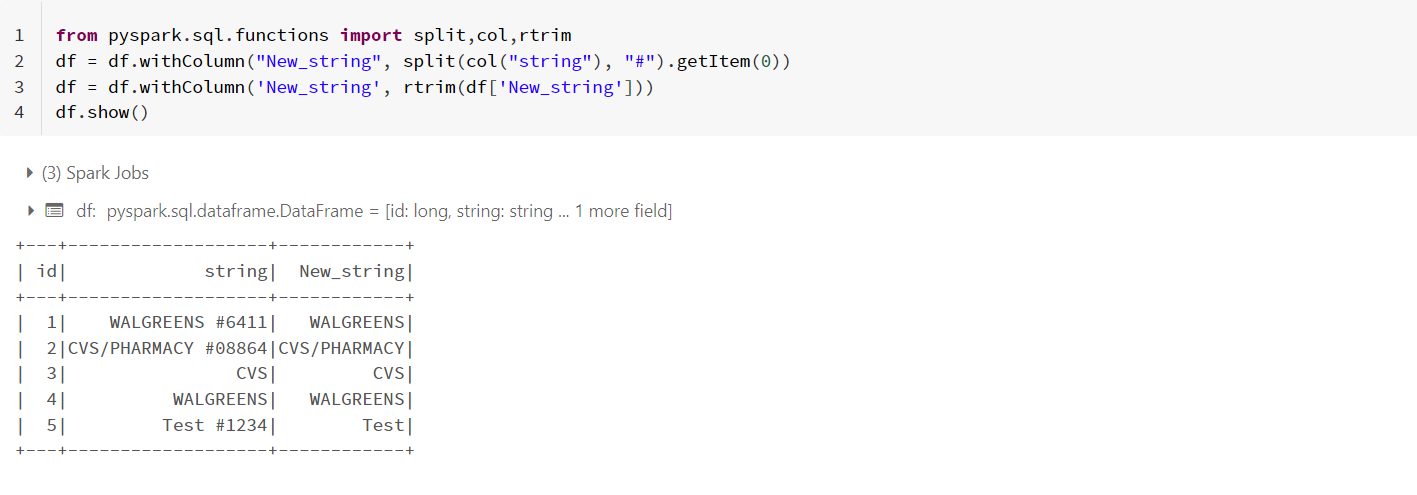
You can use split() function to achieve this. I used split function with delimiter as # to get the required value and removed leading spaces with rtrim().
- My input:
--- -------------------
| id| string|
--- -------------------
| 1| WALGREENS #6411|
| 2|CVS/PHARMACY #08864|
| 3| CVS|
| 4| WALGREENS|
| 5| Test #1234|
--- -------------------
- Try using the following code:
from pyspark.sql.functions import split,col,rtrim
df = df.withColumn("New_string", split(col("string"), "#").getItem(0))
#you can also use substring_index()
#df.withColumn("result", substring_index(df['string'], '#',1))
df = df.withColumn('New_string', rtrim(df['New_string']))
df.show()
- Output: