I have one excel with large data. I want to split this excel into multiple excel with equal distribution of rows.
My current code is working partially as it is distributing required number of rows and creating multiple excel. but at the same time it is keep creating more excel by considering the rows number.
In n_partitions if I put number 5 then it is creating excel with 5 rows in two excel and after that it keeps creating three more blank excel. I want my code to stop creating more excel after all the rows gets distributed.
Below is my sample excel with expected result and sample code.
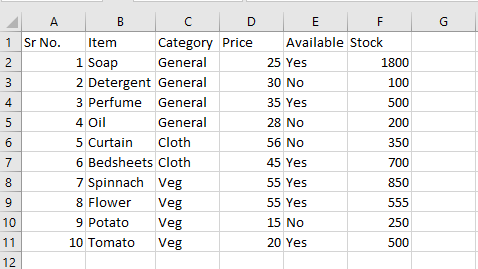
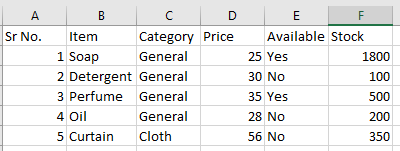
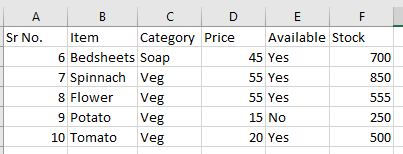
Code I am currently using is.
import pandas as pd
df = pd.read_excel("C:/Zen/TestZenAmp.xlsx")
n_partitions = 5
for i in range(n_partitions):
sub_df = df.iloc[(i*n_partitions):((i 1)*n_partitions)]
sub_df.to_excel(f"C:/Zen/-{i}.xlsx", sheet_name="a")
CodePudding user response:
You can use the code below to split your DataFrame into 5-size chunks :
n = 5
list_df = [df[i:i n] for i in range(0,df.shape[0],n)]
You can access to every chunk like this :
>>> list_df[0]
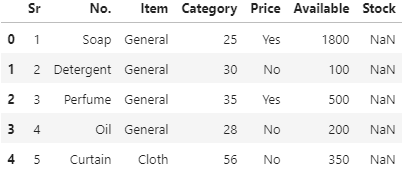
>>> list_df[2]
Then you can loop through the list of chunks/sub-dataframes and create separate Excel files :
i=1
for sub_df in list_df:
sub_df.to_excel(f"C:/Zen/-{i}.xlsx", sheet_name="a", index=False)
i =1
CodePudding user response:
Another possible solution:
g = df.groupby([df.index // k])
df['id'] = g.ngroup()
(g.apply(lambda x: x.drop('id', 1)
.to_excel(f"/tmp/x-{pd.unique(x.id)[0]}.xlsx", sheet_name="a")))