I have datafram like given below.
import pandas as pd
df = pd.DataFrame([
['server1', 'NA', 'NA', '2011-03-31'],
['server1', '2011-02-22', 'NA', 'NA'],
['server1', 'NA', '2011-06-22', 'NA'],
['server2', 'NA', 'NA', '2011-12-31'],
['server2', 'NA', '2011-02-21', 'NA'],
['server3', 'NA', 'NA', '2011-08-29'],
], columns=['hostname', 'patch_date1', 'patch_date2', 'patch_date3'])
df
i want to group data and show result like below.
server1 | 2011-02-22 | 2011-06-22 | 20211-03-31
server2 | NA | 2011-02-21 | 2011-12-31
server3 | NA | NA | 2011-08-29
CodePudding user response:
You can do this by using .replace() and .groupby() methods like :
import pandas as pd
df = pd.DataFrame([
['server1', 'NA', 'NA', '2011-03-31'],
['server1', '2011-02-22', 'NA', 'NA'],
['server1', 'NA', '2011-06-22', 'NA'],
['server2', 'NA', 'NA', '2011-12-31'],
['server2', 'NA', '2011-02-21', 'NA'],
['server3', 'NA', 'NA', '2011-08-29'],
], columns=['hostname', 'patch_date1', 'patch_date2', 'patch_date3'])
df = df.replace('NA', '').groupby('hostname').max().replace('', 'NA') # like this
print(df)
output:
patch_date1 patch_date2 patch_date3
hostname
server1 2011-02-22 2011-06-22 2011-03-31
server2 NA 2011-02-21 2011-12-31
server3 NA NA 2011-08-29
CodePudding user response:
You can use 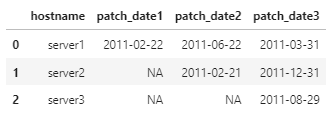
CodePudding user response:
df\
.replace("NA", np.nan)\
.groupby("hostname")\
.first()\
.reset_index()\
.fillna("NA")