I have been having some issues with my aws lambda that unzips a file inside of our s3 bucket. I created a script that would activate from a json payload that gets those passed through to it. The problem is it seems to be loosing the parent folder of the zip file and uploading the child folders underneath it. This is an issue for me as we also have another script I made to parse a log4j file inside of a folder to review for errors. That script is having problems because of the name lost that defines the farm the folder comes from.
To give an example of the issue ---
There's an s3 bucket on us-east, and inside that bucket is a key for "OriginalFolder.zip". When this lambda is activated it unzips and places the child file into the exact same bucket and place where the original zip file is but names it "Log.folder". I want it to keep the original name of the zip file so that when multiple farms are activating this lambda it doesn't overwrite that folder that's created or get confused on which one to read from with the second lambda.
I tried to append something at the end of the created file name to allow for params to be passed through for each farm that runs it but can't seem to make it work. I also contemplated having a separate action called in the script to copy and rename it using boto3 but I would rather not use that as my first choice. I feel there has to be an easier method but might be overlooking it.
Any thoughts would be helpful.
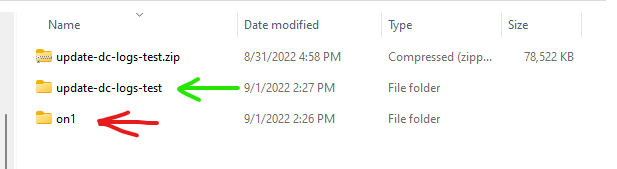
Edit: Here's a picture of the example. The green arrow is what I want it to stay named as. The red arrow is what the file is becoming named inside of our s3 environment. "on1" is the next folder inside "update-dc-logs-test".
import os
import tempfile
import zipfile
from concurrent import futures
from io import BytesIO
import boto3
s3 = boto3.client('s3')
def handler(event, context):
# Parse and prepare required items from event
global bucket, path, zipdata, rn_file
action = event.get("action", None)
if action == "create" or action == "update":
bucket = event['payload']['BucketName']
key = event['payload']['Key']
#rn_file = event['payload']['RenameFile']
path = os.path.dirname(key)
# Create temporary file
temp_file = tempfile.mktemp()
# Fetch and load target file
s3.download_file(bucket, key, temp_file)
zipdata = zipfile.ZipFile(temp_file)
# Call action method with using ThreadPool
with futures.ThreadPoolExecutor(max_workers=4) as executor:
future_list = [
executor.submit(extract, filename)
for filename in zipdata.namelist()
]
result = {'success': [], 'fail': []}
for future in future_list:
filename, status = future.result()
result[status].append(filename)
return result
def extract(filename):
# Extract zip and place it back in bucket
upload_status = 'success'
try:
s3.upload_fileobj(
BytesIO(zipdata.read(filename)),
bucket,
os.path.join(path, filename)
)
except Exception:
upload_status = 'fail'
finally:
return filename, upload_status
CodePudding user response:
You are prefixing all uploaded files with path which is the path at which the ZIP file is found. If you want the uploaded files to be stored below a prefix which is the path and name of the ZIP file (minus the .zip extension), then change the value of path to this:
path = os.path.splitext(key)[0]
Now, instead of path holding the ZIP file's folder prefix it will contain the folder prefix plus the first part of the ZIP filename. For example, if an object is uploaded to folder1/myarchive.zip then path would previously contain folder1, but with this change it will now contain folder1/myarchive.
When that new path is combined in the extract function via os.path.join(path, filename), the object will now be uploaded to folder1/myarchive/on1/file.txt.