I have a JSON list data type data. I am using json_normalize() function to read it as a CSV format. In the data, I have two types of indexing and I need both indexings in my CSV file. But for me, its showing only one level of indexing
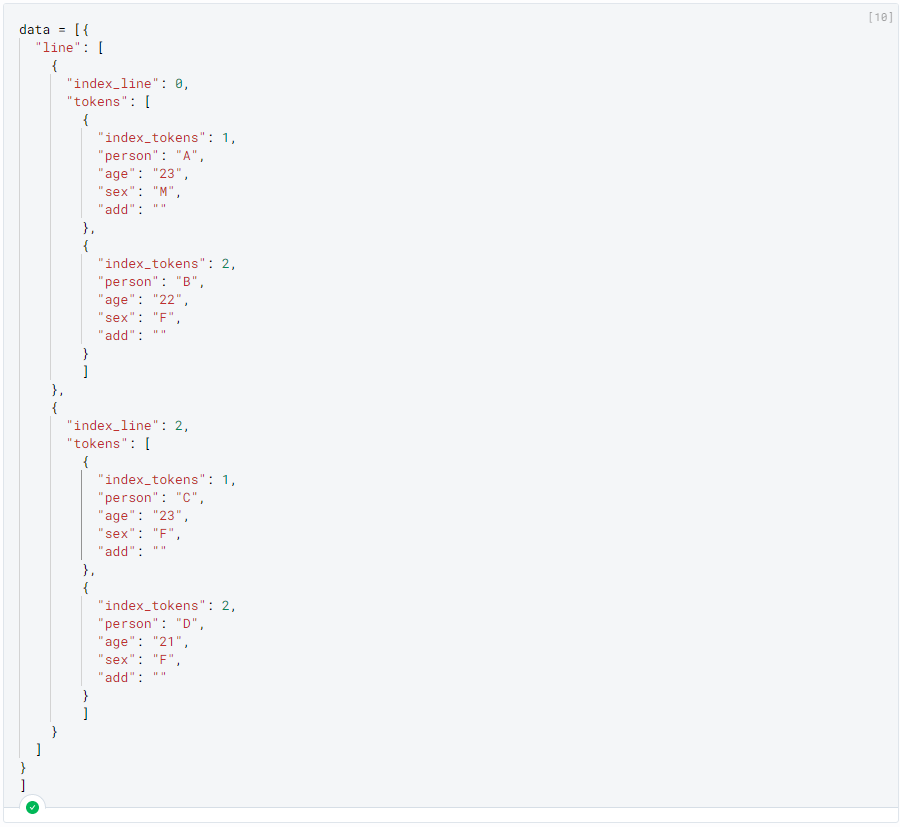
Data file:
data = [{
"line": [
{
"index_line": 0,
"tokens": [
{
"index_tokens": 1,
"person": "A",
"age": "23",
"sex": "M",
"add": ""
},
{
"index_tokens": 2,
"person": "B",
"age": "22",
"sex": "F",
"add": ""
}
]
},
{
"index_line": 2,
"tokens": [
{
"index_tokens": 1,
"person": "C",
"age": "23",
"sex": "F",
"add": ""
},
{
"index_tokens": 2,
"person": "D",
"age": "21",
"sex": "F",
"add": ""
}
]
}
]
}
]
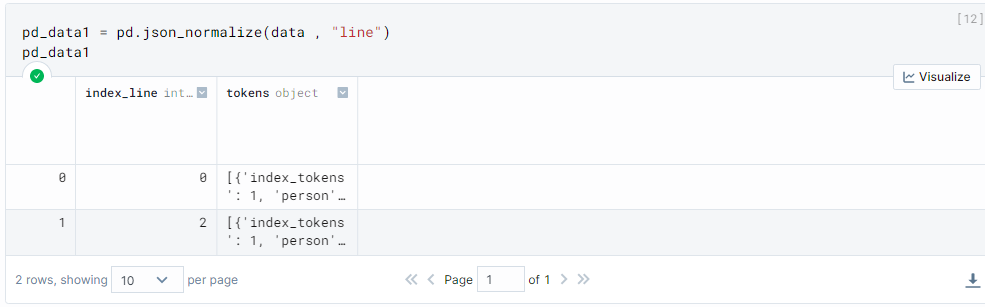
This command is showing the "index_line"
pd_data1 = pd.json_normalize(data , "line")
pd_data1
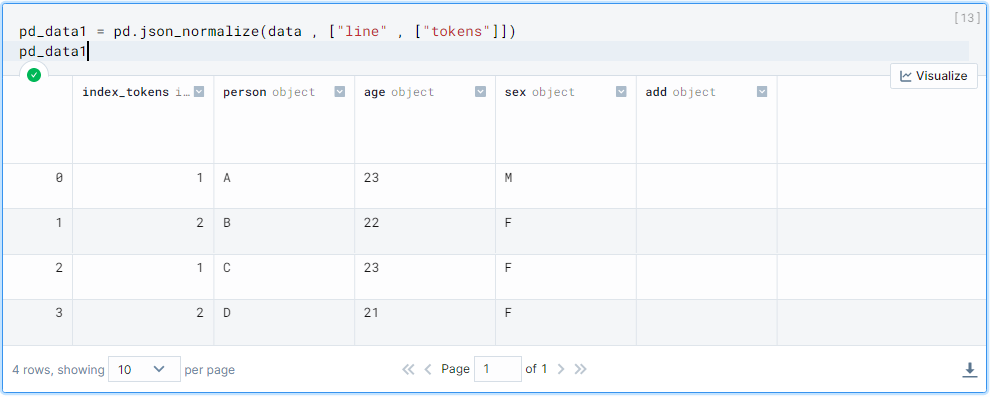
This command is showing the "index_tokens" not the "index_line". But I need both the index.
pd_data1 = pd.json_normalize(data , ["line" , ["tokens"]])
pd_data1
CodePudding user response:
Try:
df = pd.DataFrame(data[0]["line"]).explode("tokens")
df = pd.concat([df, df.pop("tokens").apply(pd.Series)], axis=1)
print(df)
Prints:
| index_line | index_tokens | person | age | sex | add | |
|---|---|---|---|---|---|---|
| 0 | 0 | 1 | A | 23 | M | |
| 0 | 0 | 2 | B | 22 | F | |
| 1 | 2 | 1 | C | 23 | F | |
| 1 | 2 | 2 | D | 21 | F |