I understand there is a way to create case expressions in SQL based on current columns. Is there a way to do this in Python with Pandas?
The goal is for Python to read an Excel file and create new columns based on conditions.
The query would start like this:
import pandas as pd
df1 = pd.read_excel('data.xlsx')
in SQL it would be read as follows:
Case
When Type = 'Banana%' THEN 'Fruit'
End
Case
When Type = 'Apple%' THEN 'Fruit'
End
Case
When Type = 'Carrot' THEN 'Vegetable'
End
The data in Excel looks like this:
| Type |
|---|
| Apple |
| Banana |
| Carrot |
CodePudding user response:
Yes, you would be able to do this:
import pandas as pd
# create an example dataframe
d = {'type':['apple', 'banana', 'carrot'],
'amount':[10, 100, 200]}
df = pd.DataFrame(d)
# change the types
df['type'] = df['type'].replace('apple','fruit')
df['type'] = df['type'].replace('banana','fruit')
df['type'] = df['type'].replace('carrot','vegitable')
# show the modified dataframe
df
which returns this:
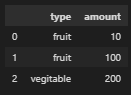
note that you could do the same in 1 line like this:
df['type'] = df['type'].replace(['apple','banana','carrot'],['fruit','fruit','vegitable'])
or with arrays, so there is a bit of additional flexibility.
CodePudding user response:
A good way is to use regular expressions
import pandas as pd
# create an example dataframe
d = {'type':['apple', 'banana', 'carrot','apple1', 'banana1', 'carrot1'],
'amount':[10, 100, 200,10,10,10]}
df = pd.DataFrame(d)
# change the types
#df['type'] = df['type'].replace(to_replace=r'^apple.$', value='fruit', regex=True)
df['type'] = df['type'].replace(regex={r'^apple(.$|$)': 'fruit', '^banana(.$|$)': 'fruit', '^carrot(.$|$)': 'vegitable'})
# show the modified dataframe
print(df)
Which would change the datatframe to
type amount
0 fruit 10
1 fruit 100
2 vegitable 200
3 fruit 10
4 fruit 10
5 vegitable 10
CodePudding user response:
You can also apply anonymous functions on your pandas series like this
import pandas as pd
# create an example dataframe
data = {'type':['apple', 'banana', 'carrot'],
'amount':[10, 100, 200]}
df = pd.DataFrame(data)
# define a function that converts value passed to type
def change_type(value: str):
if 'banana' in str(value).lower():
return 'Fruit'
elif 'apple' in str(value).lower():
return 'Fruit'
elif 'carrot' in str(value).lower():
return 'Vegetable'
# apply the function inside an anonymous function.
df['type'] = df['type'].apply(lambda value: change_type(value))
print(df)
and the output becomes
type amount
0 Fruit 10
1 Fruit 100
2 Vegetable 200