I have a dataframe like this:
df = pd.DataFrame({"ID":[1, 1],
"CLASS":["A","B"],
"TOP":[12.4, 29.1],
"BOT":[29.1, 32.8]})
I would like to create a new dataframe, but with a specific range of samples (for example, 5) between my TOP and BOT values.
I know I can create a range with 5 samples with np.linspace, but how can I put this range like two new series alternating TOP and BOT?
range_A = np.linspace(df["TOP"][df["CLASS"] == "A"].min(), df["BOT"][df["CLASS"] == "A"].min(), 5)
range_A
Out[36]: array([12.4 , 16.575, 20.75 , 24.925, 29.1 ])
range_B = np.linspace(df["TOP"][df["CLASS"] == "B"].min(), df["BOT"][df["CLASS"] == "B"].min(), 5)
range_B
Out[37]: array([29.1 , 30.025, 30.95 , 31.875, 32.8 ])
The new dataframe doesn't need to have 5 samples for each CLASS. So it should be like this:
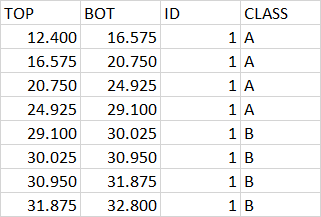
Anyone could help me?
CodePudding user response:
IIUC, you can use a function:
def topbot(d):
a = np.linspace(d['TOP'].min(), d['BOT'].max(), num=5)
return pd.DataFrame({'TOP': a[:-1], 'BOT': a[1:]})
out = (df
.groupby(['ID', 'CLASS'])
.apply(topbot)
.droplevel(-1)
.reset_index()
)
output:
ID CLASS TOP BOT
0 1 A 12.400 16.575
1 1 A 16.575 20.750
2 1 A 20.750 24.925
3 1 A 24.925 29.100
4 1 B 29.100 30.025
5 1 B 30.025 30.950
6 1 B 30.950 31.875
7 1 B 31.875 32.800
CodePudding user response:
You could do by groupby apply, then shifting the results within the groups.
df = pd.DataFrame({"ID":[1, 1],
"CLASS":["A","B"],
"TOP":[12.4, 29.1],
"BOT":[29.1, 32.8]})
df = (
df.groupby(['ID','CLASS'])
.apply(lambda x: np.linspace(x.values.min(), x.values.max(), 5))
.explode()
.reset_index(name='TOP')
.assign(BOT=lambda x: x.groupby(['ID','CLASS'])['TOP'].shift(-1))
.dropna()
)
Output
ID CLASS TOP BOT
0 1 A 12.4 16.575
1 1 A 16.575 20.75
2 1 A 20.75 24.925
3 1 A 24.925 29.1
5 1 B 29.1 30.025
6 1 B 30.025 30.95
7 1 B 30.95 31.875
8 1 B 31.875 32.8
CodePudding user response:
def func(x,n):
s = pd.Series(np.linspace(x.TOP.min(), x.BOT.min(), n))
y = pd.DataFrame(np.repeat(x.values, n - 1, axis=0), columns=x.columns)
y.TOP = s
y.BOT = s.shift(-1)
return y
df = pd.DataFrame({"ID": [1, 1],
"CLASS": ["A", "B"],
"TOP": [12.4, 29.1],
"BOT": [29.1, 32.8]})
df = df.groupby('CLASS', group_keys=False).apply(func,n=5)
print(df)
Prints:
ID CLASS TOP BOT
0 1 A 12.400 16.575
1 1 A 16.575 20.750
2 1 A 20.750 24.925
3 1 A 24.925 29.100
0 1 B 29.100 30.025
1 1 B 30.025 30.950
2 1 B 30.950 31.875
3 1 B 31.875 32.800