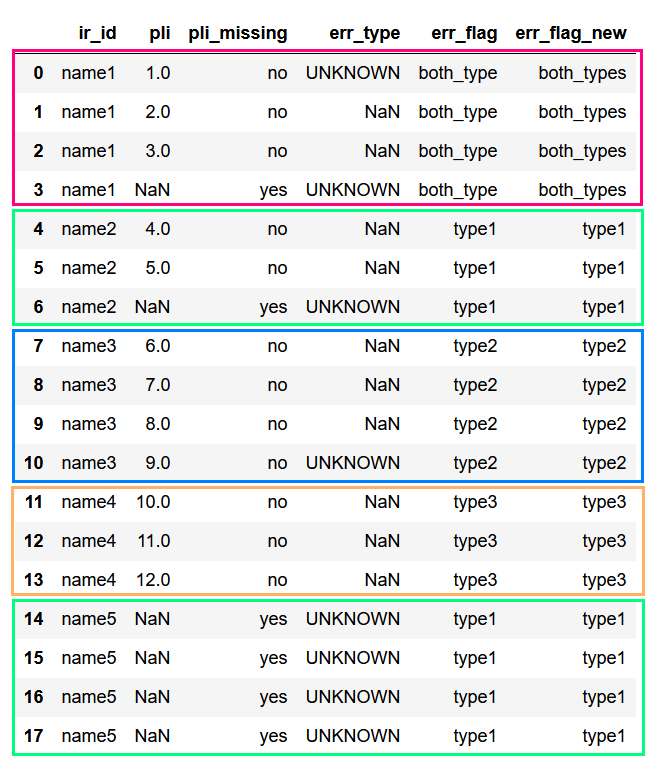
Having difficulties to create a feature based on the some groupby conditions
The data that I've looks similar to
|
ir_id |
pli |
pli_missing |
err_type |
| 0 |
name1 |
1.0 |
no |
UNKNOWN |
| 1 |
name1 |
2.0 |
no |
NaN |
| 2 |
name1 |
3.0 |
no |
NaN |
| 3 |
name1 |
NaN |
yes |
UNKNOWN |
| 4 |
name2 |
4.0 |
no |
NaN |
| 5 |
name2 |
5.0 |
no |
NaN |
| 6 |
name2 |
NaN |
yes |
UNKNOWN |
| 7 |
name3 |
6.0 |
no |
NaN |
| 8 |
name3 |
7.0 |
no |
NaN |
| 9 |
name3 |
8.0 |
no |
NaN |
| 10 |
name3 |
9.0 |
no |
UNKNOWN |
| 11 |
name4 |
10.0 |
no |
NaN |
| 12 |
name4 |
11.0 |
no |
NaN |
| 13 |
name4 |
12.0 |
no |
NaN |
| 14 |
name5 |
NaN |
yes |
UNKNOWN |
| 15 |
name5 |
NaN |
yes |
UNKNOWN |
| 16 |
name5 |
NaN |
yes |
UNKNOWN |
| 17 |
name5 |
NaN |
yes |
UNKNOWN |
I want to groupby at ir_id such that I can create err_flag column which is:
- type1: atleast 1 row having value "UNKNOWN" in
err_type column, and also "yes" in pli_missing
|
ir_id |
pli |
pli_missing |
err_type |
err_flag |
| 4 |
name2 |
4.0 |
no |
NaN |
type1 |
| 5 |
name2 |
5.0 |
no |
NaN |
type1 |
| 6 |
name2 |
NaN |
yes |
UNKNOWN |
type1 |
|
ir_id |
pli |
pli_missing |
err_type |
err_flag |
| 14 |
name5 |
NaN |
yes |
UNKNOWN |
type1 |
| 15 |
name5 |
NaN |
yes |
UNKNOWN |
type1 |
| 16 |
name5 |
NaN |
yes |
UNKNOWN |
type1 |
| 17 |
name5 |
NaN |
yes |
UNKNOWN |
type1 |
- type2: atleast 1 row having value "UNKNOWN" in
err_type column, and also "no" in pli_missing
|
ir_id |
pli |
pli_missing |
err_type |
err_flag |
| 7 |
name3 |
6.0 |
no |
NaN |
type2 |
| 8 |
name3 |
7.0 |
no |
NaN |
type2 |
| 9 |
name3 |
8.0 |
no |
NaN |
type2 |
| 10 |
name3 |
9.0 |
no |
UNKNOWN |
type2 |
- type3: no row having value "UNKNOWN" in
err_type column, and also "no" in pli_missing
|
ir_id |
pli |
pli_missing |
err_type |
err_flag |
| 11 |
name4 |
10.0 |
no |
NaN |
type3 |
| 12 |
name4 |
11.0 |
no |
NaN |
type3 |
| 13 |
name4 |
12.0 |
no |
NaN |
type3 |
- both_type: both type1 and type2 error flag, i.e.
|
ir_id |
pli |
pli_missing |
err_type |
err_flag |
| 0 |
name1 |
1.0 |
no |
UNKNOWN |
both_type |
| 1 |
name1 |
2.0 |
no |
NaN |
both_type |
| 2 |
name1 |
3.0 |
no |
NaN |
both_type |
| 3 |
name1 |
NaN |
yes |
UNKNOWN |
both_type |
Which results in final O/p as:
|
ir_id |
pli |
pli_missing |
err_type |
err_flag |
| 0 |
name1 |
1.0 |
no |
UNKNOWN |
both_type |
| 1 |
name1 |
2.0 |
no |
NaN |
both_type |
| 2 |
name1 |
3.0 |
no |
NaN |
both_type |
| 3 |
name1 |
NaN |
yes |
UNKNOWN |
both_type |
| 4 |
name2 |
4.0 |
no |
NaN |
type1 |
| 5 |
name2 |
5.0 |
no |
NaN |
type1 |
| 6 |
name2 |
NaN |
yes |
UNKNOWN |
type1 |
| 7 |
name3 |
6.0 |
no |
NaN |
type2 |
| 8 |
name3 |
7.0 |
no |
NaN |
type2 |
| 9 |
name3 |
8.0 |
no |
NaN |
type2 |
| 10 |
name3 |
9.0 |
no |
UNKNOWN |
type2 |
| 11 |
name4 |
10.0 |
no |
NaN |
type3 |
| 12 |
name4 |
11.0 |
no |
NaN |
type3 |
| 13 |
name4 |
12.0 |
no |
NaN |
type3 |
| 14 |
name5 |
NaN |
yes |
UNKNOWN |
type1 |
| 15 |
name5 |
NaN |
yes |
UNKNOWN |
type1 |
| 16 |
name5 |
NaN |
yes |
UNKNOWN |
type1 |
| 17 |
name5 |
NaN |
yes |
UNKNOWN |
type1 |
dataset used:
custom_df = pd.DataFrame.from_dict({
'ir_id':['name1', 'name1', 'name1', 'name1', 'name2', 'name2', 'name2', 'name3', 'name3', 'name3', 'name3', 'name4', 'name4', 'name4', 'name5', 'name5', 'name5', 'name5']
, 'pli': [1, 2, 3, np.nan, 4, 5, np.nan, 6, 7, 8, 9, 10, 11, 12, np.nan, np.nan, np.nan, np.nan]
, 'pli_missing': ["no","no","no","yes","no","no","yes","no","no","no","no","no","no","no","yes","yes","yes","yes"]
, 'err_type': ["UNKNOWN",np.nan,np.nan,"UNKNOWN",np.nan,np.nan,"UNKNOWN",np.nan,np.nan,np.nan,"UNKNOWN",np.nan,np.nan,np.nan,"UNKNOWN","UNKNOWN","UNKNOWN","UNKNOWN"]
, 'err_flag': ["both_type", "both_type", "both_type", "both_type", "type1", "type1", "type1", "type2", "type2", "type2", "type2", "type3", "type3", "type3", "type1", "type1", "type1", "type1"]
})
custom_df
PS
Earlier