For example, I have a following df:
| score | var1 |
|---|---|
| 0.465 | jack, jones, phil |
| 0.712 | don, sam, bob |
| 0.112 | jones, alex, sam |
I want to round column 'score' in such a way, so I would have for example a mean score of jones in such a way
| name | 0.1 (score) | 0.5 |
|---|---|---|
| jones | 1 | 1 |
| jack | 0 | 1 |
| alex | 0 | 0 |
second and third column, are the rounded score, so if we have max score of 1, then we will have 10 column, and as shown in table above, it shows how much jones appeared with the rounded score of 0.1 and etc
I have a code written to similiar question as this, but instead of a score I just have boolean target column with 0 and 1. however, I cant figure how to do it in this case this is the code:
out=(df
.assign(cr_social_vector=df['var_1'].str.split(',\s*'),
dev_var=np.where(df['target'].eq(1), 'dev_var_1', 'dev_var_0'),
value=1
)
.explode('cr_social_vector')
.pivot_table(index=['var_1', 'var_2'], columns='target', values='value',
aggfunc='sum', fill_value=0)
.reset_index().rename_axis(columns=None)
.groupby(['var_1'], as_index=False)
.agg({'target_1': 'sum', 'target_0': 'sum', 'var_2': 'last'})
)
CodePudding user response:
You can try
out_ = (df.assign(score=df['score'].round(1),
var1=df['var1'].str.split(', '))
.explode('var1'))
out = pd.crosstab(out_['var1'], out_['score'])
print(out_)
score var1
0 0.5 jack
0 0.5 jones
0 0.5 phil
1 0.7 don
1 0.7 sam
1 0.7 bob
2 0.1 jones
2 0.1 alex
2 0.1 sam
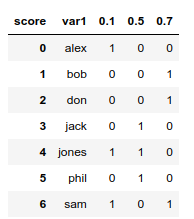
print(out)
score 0.1 0.5 0.7
var1
alex 1 0 0
bob 0 0 1
don 0 0 1
jack 0 1 0
jones 1 1 0
phil 0 1 0
sam 1 0 1
CodePudding user response:
You can use