I have a list of pandas timestamps in the following format:
[Timestamp('2022-01-01 21:00:00'),
Timestamp('2022-01-02 21:15:00'),
Timestamp('2022-01-03 21:00:00'),
Timestamp('2022-01-04 20:00:00'),
Timestamp('2022-01-05 21:00:00'),
....
]
Now what I want to do is basically look at the time of the day and plot a histogram which denotes how much percentage of these stamps are at 21:00, 21:15 etc. I know I can extract the hour and minute from the timestamps but having trouble figuring out how to plot the histogram where the labels would be the hours and minute and the bars would represent the percentage.
So, my attempt is as follows:
labels, counts = np.unique(histogram, return_counts=True)
all_sum = sum(counts)
percentages = [i * 100 / all_sum for i in counts]
bars = plt.bar(labels, counts, align="center", width=13, color="blue", edgecolor="black")
for i, p in enumerate(bars):
width = p.get_width()
height = p.get_height()
x, y = p.get_xy()
print(x, y)
plt.text(x width / 2, y height * 1.01, "{0:.2f}".format(percentages[i]) "%", ha="center", weight="bold")
plt.gca().set_xticks(labels)
plt.grid(False)
plt.tight_layout()
plt.show()
However, this results in a plot as follows:
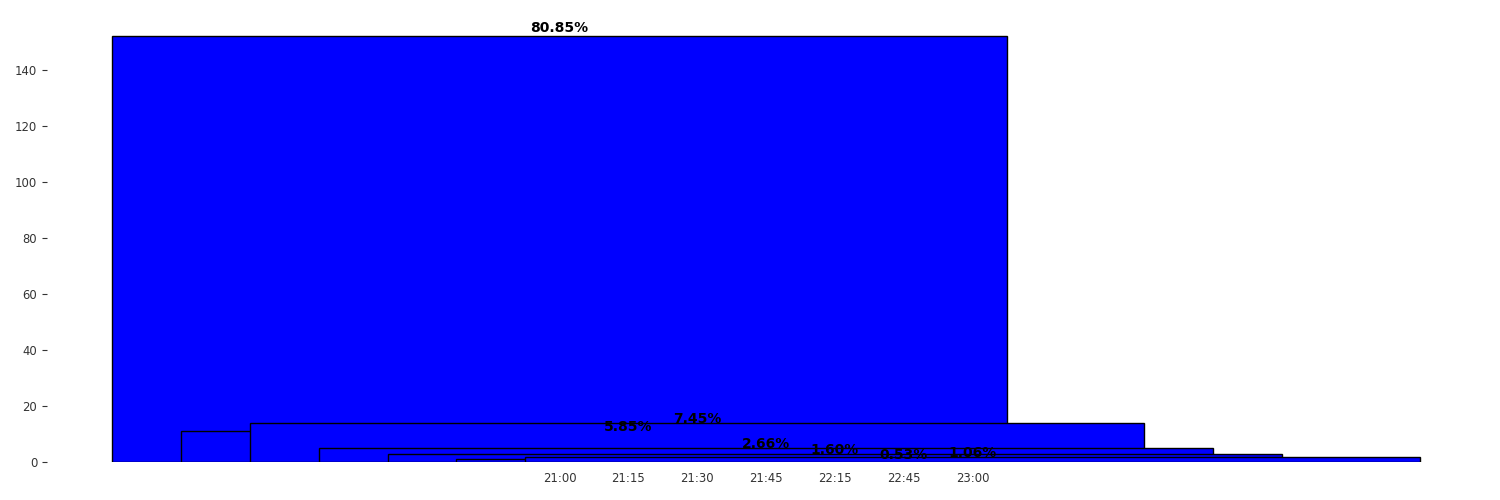
Not sure why these bars are overlapping...
CodePudding user response:
Generate appropriately formatted strings from the datetimes, group by the strings, count, and leverage the pandas plotting methods:
import pandas as pd
import matplotlib.ticker as mtick
import matplotlib.pyplot as plt
datetimes = [('2022-01-01 21:00:00'),
('2022-01-02 21:15:00'),
('2022-01-03 21:00:00'),
('2022-01-04 20:00:00'),
('2022-01-05 21:00:00'),]
df = pd.DataFrame({"datetime": pd.to_datetime(datetimes)})
fig, ax = plt.subplots(1, 1)
((df.groupby(df.datetime.dt.strftime("%H:%M")).size() / len(df) * 100)
.plot.bar(ax=ax))
ax.yaxis.set_major_formatter(mtick.PercentFormatter())
ax.grid(False)