I'm working on a table counting around 40,000,000 rows, and I'm trying to extract first entry for each "subscription_id" (foreign key from another table), here is my acutal request:
SELECT * FROM billing bill WHERE bill.billing_value not like 'not_ok%'
AND
(SELECT bill2.billing_id
FROM billing bill2
WHERE bill2.subscription_id = bill.subscription_id
ORDER BY bill2.billing_id ASC LIMIT 1
)= bill.billing_id;
This request is working correctly, when I put a small limit on it, but I cannot seem to process it for all the database.
Is there a way I could optimise it somehow ? Or do things in an other way ?
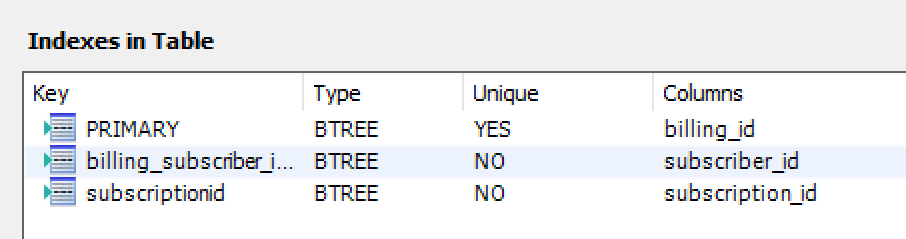
Table indexes and structure:

Indexes:
CodePudding user response:
This is an example of the ROW_NUMBER() solution mentioned in the comments above.
select *
from (
select *, row_number() over (partition by subscription_id order by billing_id) as rownum
from billing
where billing_value not like 'not_ok%'
) t
where rownum = 1;
The ROW_NUMBER() function is available in MySQL 8.0, so if you haven't upgraded yet, you must do so to use this function.
Unfortunately, this won't be much of an improvement, because the NOT LIKE causes a table-scan regardless of the pattern you search for.
I believe it requires a virtual column with an index to optimize that condition:
alter table billing
add column ok as tinyint(1) as (billing_value not like 'not_ok%'),
add index (ok);
select *
from (
select *, row_number() over (partition by subscription_id order by billing_id) as rownum
from billing
where ok = true
) t
where rownum = 1;
Now it will use the index on the ok virtual column to reduce the set of examined rows.
This still might be a costly query on a 40 million row table, because the derived table subquery creates a large temporary table. If it's not fast enough, you'll have to really reconsider how you store and query this data.
For example, adding a column first_ok with an index, which is true only on the rows you need to fetch (the first row per subscriber_id without 'not_ok' as the billing value). But you must maintain this new column manually, and risk it being wrong if you don't do that. This is a denormalized design, but tailored to the query you want to run.
CodePudding user response:
I haven't tried it, because I don't have an MySQL DB at hand, but this query seems much simpler:
select *
from billing
where billing_id in (select min(billing_id)
from billing
group by subscription_id)
and billing_value not like 'not_ok%';
The inner select get the minimum billing_id for all subscriptions. The outer gets the rest of the billing record.
If performance is an issue, I'd add the billing_id field in the third index, so you get an index with (subscription_id,billing_id). This will help for the inner query.