I am trying to read a csv compressed file from S3 using pandas.
The dataset has 2 date columns, or at least they should be parsed as dates, I have read pandas docs and using parse_dates=[col1, col2] should work fine. Indeed it parsed one column as date but not the second one, which is something weird because they have the same formatting (YYYYmmdd.0), and both have Nan values as shown below 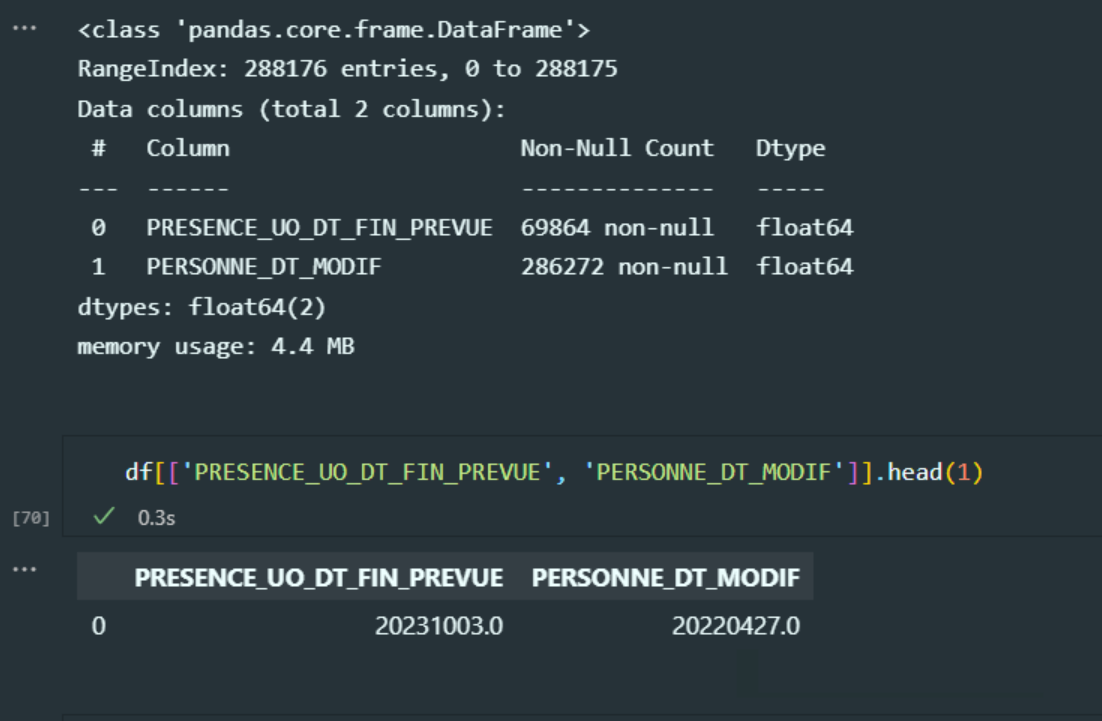
I read the file as follow :
date_columns = ['PRESENCE_UO_DT_FIN_PREVUE', 'PERSONNE_DT_MODIF']
df = s3manager_in.read_csv(object_key='Folder1/file1', sep=';', encoding = 'ISO-8859-1', compression = 'gzip', parse_dates=date_columns, engine='python')
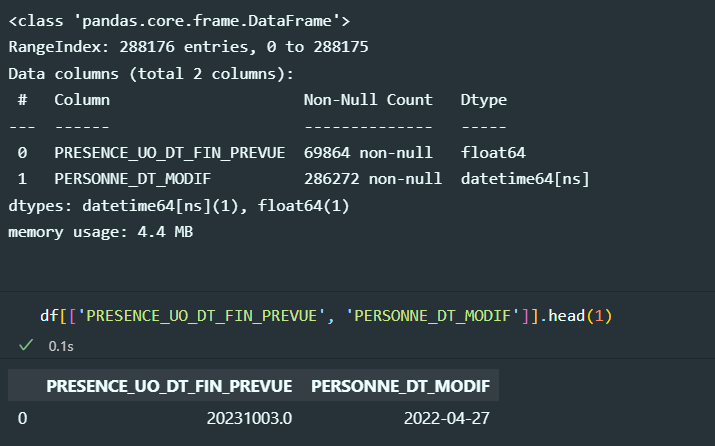 Is there any explanation why 1 column get parsed as date and the second one is not ?
Is there any explanation why 1 column get parsed as date and the second one is not ?
Thanks
CodePudding user response:
The column 'PRESENCE_UO_DT_FIN_PREVUE' seems to carry some "bad" values (that are not formatted as 'YYYYmmdd.0'). That's probably the reason why pandas.read_csv can't parse this column as a date even with passing it as an argument of the parameter parse_dates.
Try this :
df = s3manager_in.read_csv(object_key='Folder1/file1', sep=';', encoding = 'ISO-8859-1', compression = 'gzip', engine='python')
date_columns = ['PRESENCE_UO_DT_FIN_PREVUE', 'PERSONNE_DT_MODIF']
df[date_columns ] = df[date_columns].apply(pd.to_datetime, errors='coerce')
Note that the 'coerce' in pandas.to_datetime will put NaN instead of every bad value in the column 'PRESENCE_UO_DT_FIN_PREVUE'.
errors{‘ignore’, ‘raise’, ‘coerce’}, default ‘raise’ :
If ‘coerce’, then invalid parsing will be set as NaN.
CodePudding user response:
Found out what was wrong with the column, in fact -as my collegue pointed out- the column has some values that exceed Python maximum value to be parsed as date in Python.
Pandas maximum datetime is Timestamp.max=Timestramp('2262-04-11 23:47:16.854775807')
and it happened that values in that column can be : df.loc['PRESENCE_UO_DT_FIN_PREVUE'].idxmax()]['RESENCE_UO_DT_FIN_PREVUE'] = 99991231.0
The problem is read_csv with parse_dates is not generating any errors or warning, so it is difficult to find out what's is wrong.
So to encounter this problem, I manually convert the column:
def date_time_processing(var):
#if var == 99991231.0 or var == 99991230.0 or var == 29991231.0 or var == 99991212.0 or var == 29220331.0 or var == 30000131.0 or var == 30001231.0:
if var > 21000000.0 :
return (pd.Timestamp.max).strftime('%Y%m%d')
elif var is np.nan :
return pd.NaT
else :
return (pd.to_datetime(var, format='%Y%m%d'))
and then give it a lambda function :
df['PRESENCE_UO_DT_FIN_PREVUE'] = df['PRESENCE_UO_DT_FIN_PREVUE'].apply(lambda x:date_time_processing(x)