I have a dataframe like below:
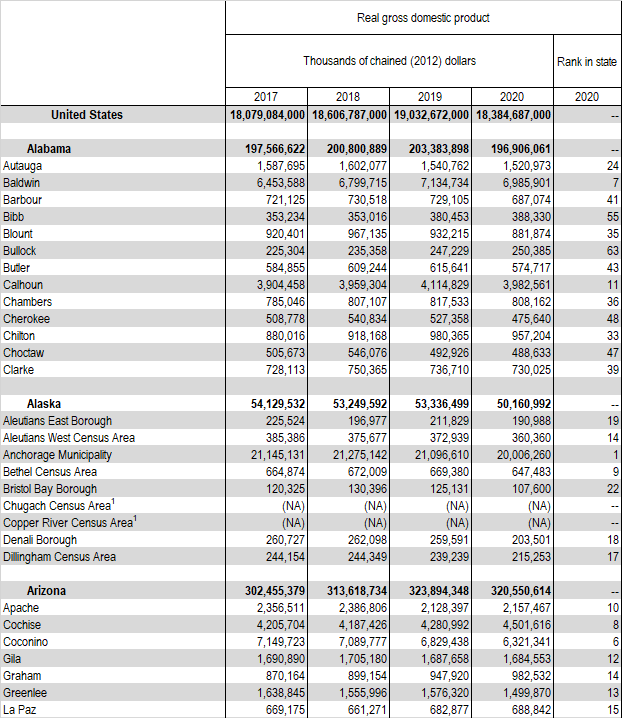
But I want to have new data frame with the sate is a seperate column as below:
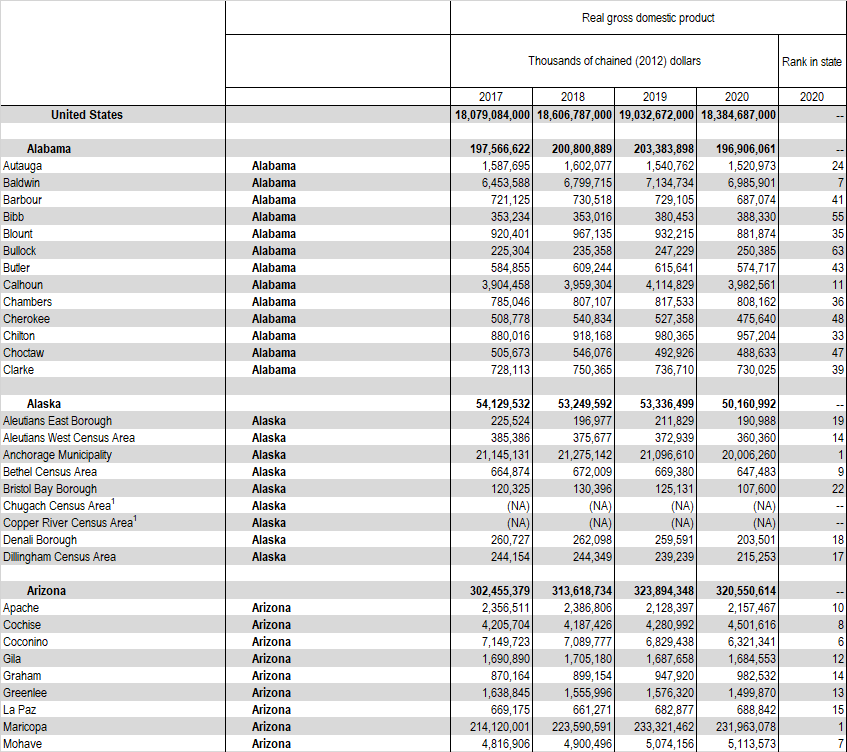
DO you know how to do it using Python? Thank you so much.
CodePudding user response:
If you provide an example dataset it would be helpful and we can work on it. I created an example dataset like the table below:
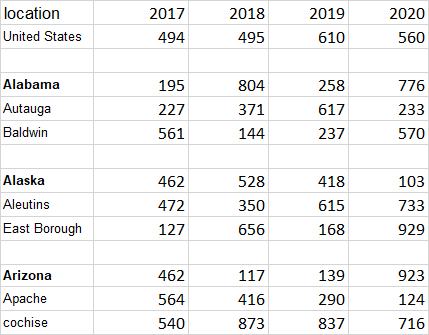
numbers were given randomly.
I am not sure if there is an easy way. You should put all your states in a list beforehand. The main idea behind my approach is detecting the empty rows between the states. The first string coming after the empty row is the state name and filling this name until the empty row is reached. (since there might be another country name like the United States and probably comes from an empty row, we created the states list beforehand to avoid mistakes.) Here is my approach:
import pandas as pd
import numpy as np
data = pd.read_excel("data.xlsx")
states = ["Alabama","Alaska","Arizona"]
data['states'] = np.nan #creating states column
flag = ""
for index, value in data['location'].iteritems():
if pd.notnull(value):
if value in states:
flag = value
data['states'].iloc[index] = flag
#relocating 'states' column to the second position in the dataframe
column = data.pop('states')
data.insert(1,'states',column)
And the result:
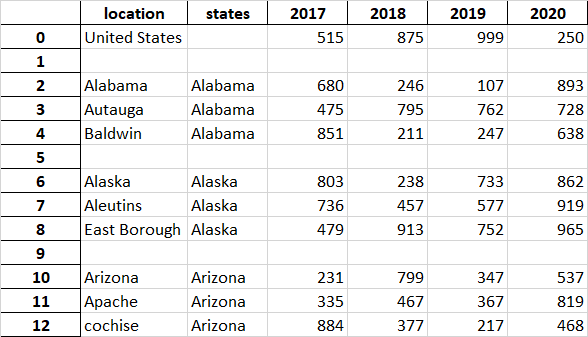
CodePudding user response:
Well, let's say we have this data:
data = {
'County':[
' USA',
'',
' Alabama',
'Autauga',
'Baldwin',
'Barbour',
'',
' Alaska',
'Aleutians',
'Anchorage',
'',
' Arizona',
'Apache',
'Cochise'
]
}
df = pd.DataFrame(data)
We could use empty lines as marks of a new state like this:
spaces = (df.County == '')
states = spaces.shift().fillna(False)
df['States'] = df.loc[states, 'County']
df['States'].ffill(inplace=True)
In the code above states is a mask of cells under empty lines, where states are located. At the next step we connect states by genuine index to the new column. After that we apply forward fill of NaN values which will duplicate each states until the next one.
Additionally we could do some cleaning. This, IMO, would be more relevant somewhat earlier, but anyway:
df['States'] = df['States'].fillna('')
df.loc[spaces, 'States'] = ''
df.loc[states, 'States'] = ''
This method rely on the structure with spaces between states. Let's make something different in case if there's no spaces between states. Say we have some data like this (no empty rows, no spaces around names):
data = [
'USA',
'Alabama',
'Autauga',
'Baldwin',
'Barbour',
'Alaska',
'Aleutians',
'Anchorage',
'Arizona',
'Apache',
'Cochise'
]
df = pd.DataFrame(data, columns=['County'])
We can work with a list of known states and pandas.Series.isin in this case. All the other logic can stay the same:
States = ['Alabama','Alaska','Arizona',...]
mask = df.County.isin(States)
df = df.assign(**{'States':df.loc[mask, 'County']}).ffill()