People of stack overflow, help!
I have a leetcode style problem for you guys.
Imagine a scenario where you have 2 2D arrays, more specifically 2 Dataframes with pandas.
I need to compare these 2 Dataframes and highlight all the differences, however there is a catch. Rows can be missing from these data frames which makes this inherently a lot more difficult, as well as missing cells too. I'll provide an example.
import pandas as pd
x = [[0, 1, 2, 3],[4, 5, 6, 7],[8, 9, 10, 11],[12, 13, 14, 15]]
y = [[nan, 1, 2, 3],[4, 5, 6, nan],[12, 13, 14, 15]]
df1 = pd.DataFrame(x)
df2 = pd.DataFrame(y)
How can I identify all of the missing cells AND the missing rows?
Bonus points if you can create code to highlight the differences and export them to an excel sheet ;)
CodePudding user response:
Stage 1
A good starting point would be the following StackOverflow question: 
and "df" the dataframe you are comparing it to.
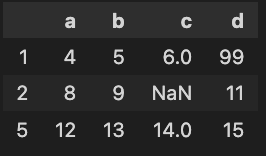
The differences are:
- rows 0 and 3 missing
- a new row (5)
- (0, "d") is equal to 99 instead of 3
- (2, "c") is NaN instead of 10
solution
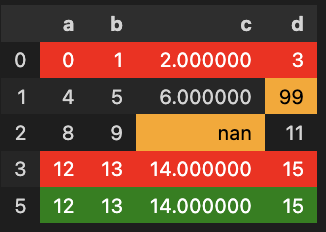
The following solution highlights:
- [in red] the "deleted rows" (row indexes that don't appear in df)
- [in green] the "new rows" (row indexes that don't appear in df_ref)
- [in orange] the values that differ for common rows
def get_dataframes_diff(df: pd.DataFrame, df_ref: pd.DataFrame, path_excel = None):
rows_new = df.index[~df.index.isin(df_ref.index)]
rows_del = df_ref.index[~df_ref.index.isin(df.index)]
rows_common = df_ref.index.intersection(df.index)
df_diff = pd.concat([df, df_ref.loc[rows_del]]).sort_index()
s = df_diff.style
def format_row(row, color: str = "white", bg_color: str = "green"):
return [f"color: {color}; background-color: {bg_color}"] * len(row)
s.apply(format_row, subset = (rows_new, df.columns), color="white", bg_color="green", axis=1)
s.apply(format_row, subset = (rows_del, df.columns), color="white", bg_color="red", axis=1)
mask = pd.DataFrame(True, index=df_diff.index, columns=df_diff.columns)
mask.loc[rows_same] = (df_ref.loc[rows_same] == df.loc[rows_same])
mask.replace(True, None, inplace=True)
mask.replace(False, "color: black; background-color: orange;", inplace=True)
s.apply(lambda _: mask, axis=None)
if path_excel is not None:
s.to_excel(path_excel)
return s
It gives:
get_dataframes_diff(df, df_ref)
explanation
get the list of deleted rows, new rows and those in common
rows_new = df.index[~df.index.isin(df_ref.index)]
rows_del = df_ref.index[~df_ref.index.isin(df.index)]
rows_same = df_ref.index.intersection(df.index)
create a "diff" dataframe, by adding the deleted rows to the df dataframe
df_diff = pd.concat([df, df_ref.loc[rows_del]]).sort_index()
Use Styler.apply to highlight in green the new rows, and red the lines deleted (note the use of the subsetargument):
def format_row(row, color: str = "white", bg_color: str = "green"):
return [f"color: {color}; background-color: {bg_color}"] * len(row)
df_diff.style.apply(format_row, subset = (rows_new, df.columns), color="white", bg_color="green", axis=1)
df_diff.style.apply(format_row, subset = (rows_del, df.columns), color="white", bg_color="red", axis=1)
To highlight value differences for common rows, create a mask dataframe which equals True for elements that are the same, and False when values differ
mask = pd.DataFrame(True, index=df_diff.index, columns=df_diff.columns)
mask.loc[rows_common] = (df_ref.loc[rows_common] == df.loc[rows_common])
When True (same value), we don't apply any styling. When False, we highlight in orange:
mask.replace(True, None, inplace=True)
mask.replace(False, "color: black; background-color: orange;", inplace=True)
df_diff.style.apply(lambda _: mask, axis=None)
Finally if you want to save it as an excel file, provide a valid path to the path_excel argument.