I have the following dataframe which I'm wanting to create 3 new dataframes from using the values in specific columns (ppbeid, initpen and incpen) and using the unique entries in the benid and id columns:
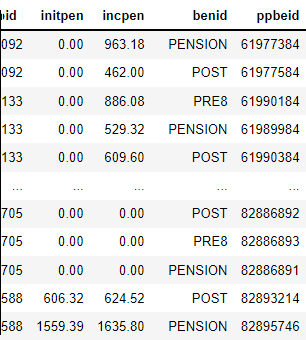
In part of my code, below, I'm using a list of unique items in the benid column, then removing any blanks from the list. This will give me some of the column headers I want in the new dataframes, but I also want the unique ids in the id column, the aforementioned list of unique benid items and, for a couple of the new dataframes, a total column too (see last 3 Excel screenshots):
lst_benids = df_ppbens.benid.unique()
lst_benids = list(filter(None, lst_benids))
# Result is: ['PENSION', 'POST', 'PRE8', 'SPOUSE', 'RULE29', 'MOD']I know how to achieve this in Excel using Index/Match/Match, but it's long-winded and I really want to learn how to do this in Pandas. The output should be the following 3 dataframes (which I'll then export to Excel in different worksheets):
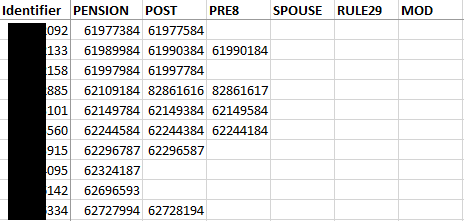
First dataframe should be what the ppbeid column entry is, for the corresponding benid field, listed by the unique ids:
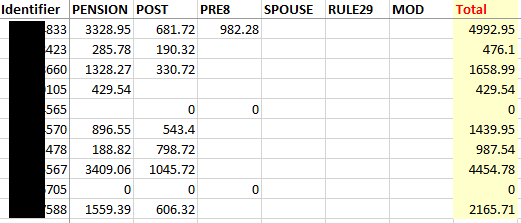
The second dataframe should be the initpen figures for those unique ids are and the specific corresponding benid, with a total column at the end:
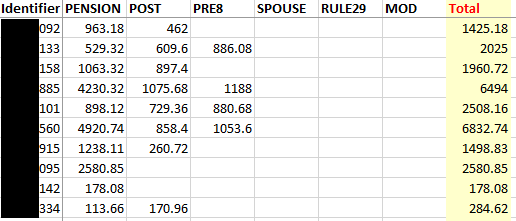
The third and final dataframe is the same as above but instead it's got the incpen column figures for corresponding benids and a total column at the end:
Any help is much appreciated and it will help me learn something I have to do manually in Excel a lot. Being new to Pandas/Python, I'm finding it confusing navigating the documents and other resources online. Thanks
CodePudding user response:
It seems like what you want can be done with the pivot method, which is similar to Excel's pivot table.
First let's set up the data:
df = pd.DataFrame(
{
"id": [92, 92, 133, 133, 133, 705, 705, 705, 588, 588],
"initpen": [0] * 8 [606.32, 1559.39],
"incpen": [963.18, 462, 886.08, 529.32, 609.6, 0, 0, 0, 624.52, 1635.8],
"benid": ["PENSION", "POST", "PRE8", "PENSION", "POST", "POST", "PRE8", "PENSION", "POST", "PENSION",],
# I got tired of typing out the whole numbers...
"ppbeid": [6197, 6197, 61990, 61998, 61990, 828, 828, 828, 8289, 8289],
}
)
Then you can simply do:
df1 = df.pivot(index='id', columns='benid', values='ppbeid')
And for the others, substitute the appropriate variable name for ppbeid.
The to add the total just do:
df1['Total'] = df1.sum(1)
CodePudding user response:
Alternate solution, although Josh's answer did point me in the right direction. Instead of using pivot, I'm using pd.pivot_table.
For the first dataframe that I needed, I used:
df1 = pd.pivot_table(df, index='pempid', columns='benid', values='ppbeid', dropna=False, fill_value='')
For the other two dataframes that I needed, I passed in additional parameters aggfunc (to sum up my rows), margins (to get a total column) and margins_name (the header for the total column). I did this separately for both initpen and incpen by changing the values parameter:
df_initpen = pd.pivot_table(df, index='pempid', columns='benid', values='initpen', dropna=False, fill_value=0, aggfunc='sum', margins=True, margins_name='Total')
This Python Pivot Tables Tutorial - YouTube video has more details on how to use pd.pivot_table and helped me arrive to this solution.