A little background...
Everything I'm about to describe up to my implementation of the StreamWriter is business processes which I cannot change.
Every month I pull around 200 different tables of data into individual files. Each file contains roughly 400,000 lines of business logic details for upwards of 5,000-6,000 different business units.
To effectively use that data with the tools on hand, I have to break down those files into individual files for each business unit...
200 files x 5000 business units per file = 100,000 different files.
The way I've BEEN doing it is the typical StreamWriter loop...
foreach(string SplitFile in List<BusinessFiles>)
{
using (StreamWriter SW = new StreamWriter(SplitFile))
{
foreach(var BL in g)
{
string[] Split1 = BL.Split(',');
SW.WriteLine("{0,-8}{1,-8}{2,-8}{3,-8}{4,-8}{5,-8}{6,-8}{7,-8}{8,-8}{9,-16}{10,-1}",
Split1[0], Split1[1], Split1[2], Split1[3], Split1[4], Split1[5], Split1[6], Split1[7], Split1[8], Convert.ToDateTime(Split1[9]).ToString("dd-MMM-yyyy"), Split1[10]);
}
}
}
The issue with this is, It takes an excessive amount of time. Like, It can take 20 mins to process all the files sometimes.
Profiling my code shows me that 98% of the time spent is on the system disposing of the StreamWriter after the program leaves the loop.
So my question is......
Is there a way to keep the underlying Stream open and reuse it to write a different file?
I know I can Flush() the Stream but I can't figure out how to get it to start writing to another file altogether. I can't seem to find a way to change the destination filename without having to call another StreamWriter.
Edit:
A picture of what it shows when I profile the code
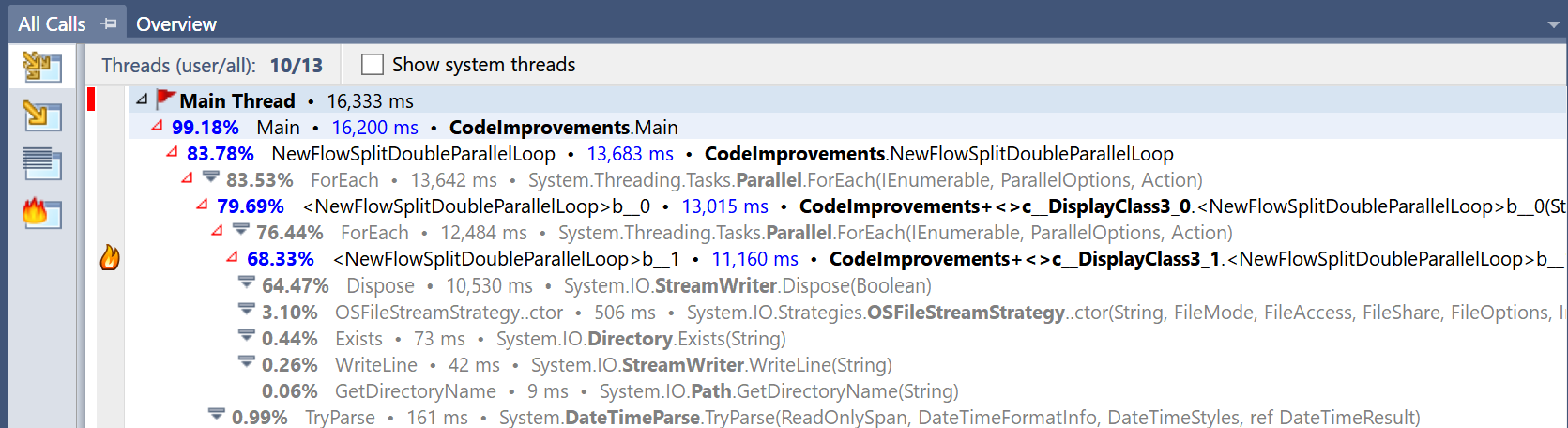
CodePudding user response:
This sounds about right. 100,000 files in 20 minutes is more than 83 files every second. Disk I/O is pretty much the slowest thing you can do within a single computer. All that time in the Dispose() method is waiting for the buffer to flush out to disk while closing the file... it's the actual time writing the data to your persistent storage, and a separate using block for each file is the right way to make sure this is done safely.
To speed this up it's tempting to look at asynchronous processing (async/await), but I don't think you'll find any gains there; ultimately this is an I/O-bound task, so optimizing for your CPU scheduling might even make things worse. Better gains could be available if you can change the output to write into a single (indexed) file, so the operating system's disk buffering mechanism can be more efficient.
CodePudding user response:
Responding to your question, you have an option (add a flag on the constructor) but it is strongly tied to the garbage collector, also think about multi thread environment it could be a mess. That said this is the overloaded constructor:
StreamWriter(Stream, Encoding, Int32, Boolean)
Initializes a new instance of the StreamWriter class for the specified stream by using the specified encoding and buffer size, and optionally leaves the stream open.
public StreamWriter (System.IO.Stream stream, System.Text.Encoding? encoding = default, int bufferSize = -1, bool leaveOpen = true);
CodePudding user response:
I would agree with Joel that the time is mostly due to writing the data out to disk. I would however be a little bit more optimistic about doing parallel IO, since SSDs are better able to handle higher loads than regular HDDs. So I would try a few things:
1. Doing stuff in parallel
Change your outer loop to a parallel one
Parallel.ForEach(
myBusinessFiles,
new ParallelOptions(){MaxDegreeOfParallelism = 2},
SplitFile => {
// Loop body
});
Try changing the degree of parallelism to see if performance improves or not. This assumes the data is thread safe.
2. Try writing high speed local SSD
I'm assuming you are writing to a network folder, this will add some additional latency, so you might try to write to a local disk. If you are already doing that, consider getting a faster disk. If you need to move all the files to a network drive afterwards, you will likely not gain anything, but it can give an idea about the penalty you get from the network.
3. Try writing to a Zip Archive
There are zip archives that can contain multiple files inside it, while still allowing for fairly easy access of an individual file. This could help improve performance in a few ways:
- Compression. I would assume your data is fairly easy to compress, so you would write less data overall.
- Less file system operations. Since you are only writing to a single file you would avoid some overhead with the file system.
- Reduced overhead due to cluster size. Files have a minimum size, this can cause a fair bit of wasted space for small files. Using an archive avoids this.
You could also try saving each file in an individual zip-archive, but then you would mostly benefit from the compression.