The Goal
The goal is interpret plain text content and recognise patterns e.g. Arithmetic, Comments, Units of Measurements.
Example Input
This would be entered by a user.
# This is an example comment
10 10
// Another comment
This is one line of text
Tested
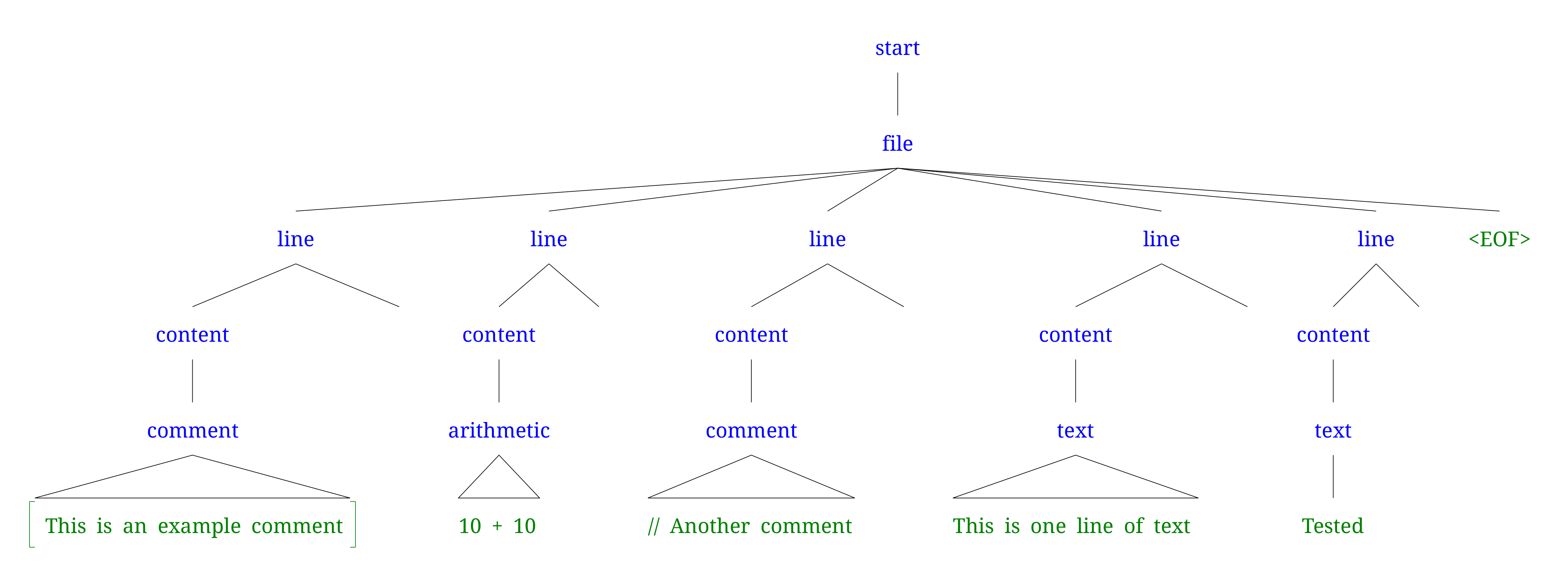
Expected Parse Tree
The goal of my grammar is to generate a tree that would look like this (if anyone has a better method I'd be interested to hear).
Note: The 10 10 is being recognised as an arithmetic rule.
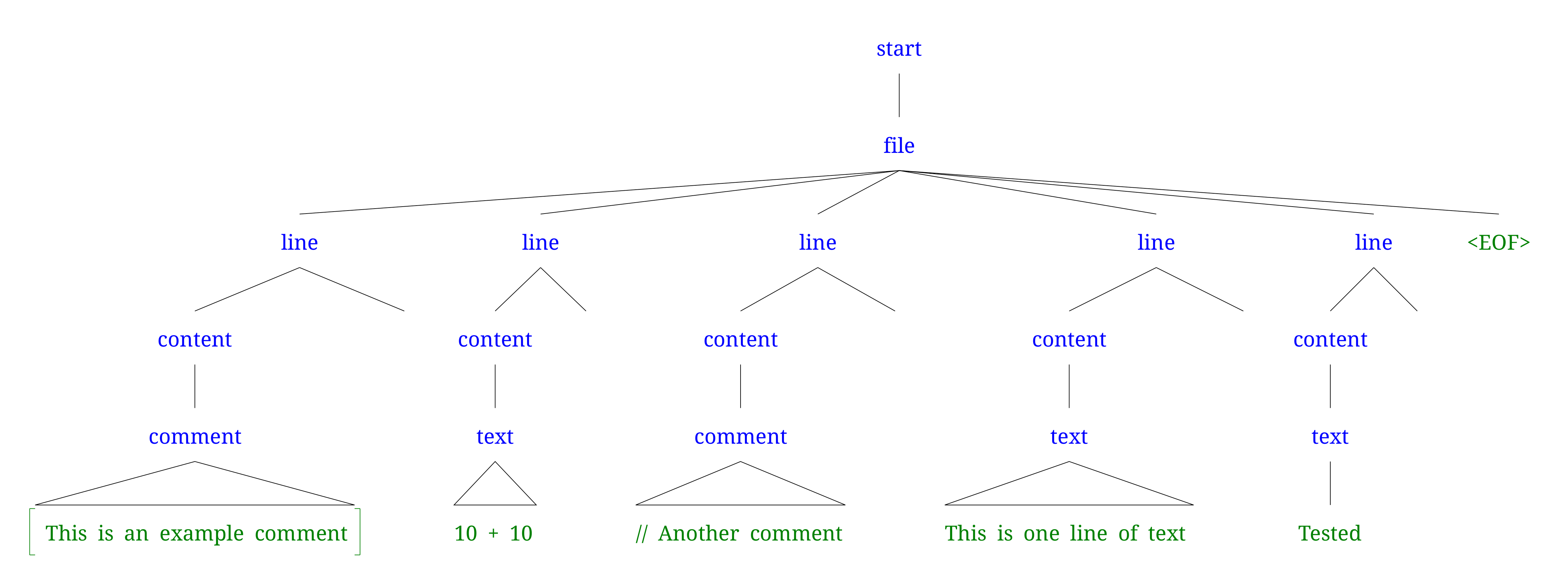
Current Parse Tree aka The Problem
Below is the current output from the lexer and parser.
Note: The 10 10 is being recognised as an text and not the arithmetic rule.
Grammar Definition
The logic of the grammar at a high levels is as follows:
- Parse line by line
- Determine the line content if not fall back to text
grammar ContentParser;
/*
* Tokens
*/
NUMBER: '-'? [0-9] ;
LPARAN: '(';
RPARAN: ')';
POW: '^';
MUL: '*';
DIV: '/';
ADD: ' ';
SUB: '-';
LINE_COMMENT: '#' TEXT | '//' TEXT;
TEXT: ~[\n\r] ;
EOL: '\r'? '\n';
/*
* Rules
*/
start: file;
file: line EOF;
line: content EOL;
content
: comment
| arithmetic
| text
;
// Custom Content Types
comment: LINE_COMMENT;
/// Example taken from ANTLR Docs
arithmetic:
NUMBER # Number
| LPARAN inner = arithmetic RPARAN # Parentheses
| left = arithmetic operator = POW right = arithmetic # Power
| left = arithmetic operator = (MUL | DIV) right = arithmetic # MultiplicationOrDivision
| left = arithmetic operator = (ADD | SUB) right = arithmetic # AdditionOrSubtraction;
text: TEXT;
My Understanding
The content rule should check for a match of the comment rule then followed by the arithmetic rule and finally falling back to the text rule which matches any character apart from newlines.
However, I believe that the lexer is being greedy on the TEXT tokens which is causing issues but I'm not sure.
(I'm still learning ANTLR)
CodePudding user response:
When you are writing a parser, it's always a good idea to print out the tokens for the input.
In the current grammar, 10 10 is recognized by the lexer as TEXT, which is not what is needed. The reason it is text is because that is the longest string matched by a rule. It does not matter in this case that the TEXT rule occurs after the NUMBER rule in the grammar. The rule is that Antlr lexers will always match the longest string possible of the given lexer rules. But, if it can match two or more lexer rules where the strings are of equal length, then the first rule "wins". The lexer works pretty much independently of the parser.
There is no way to reliably have spaces in a text string, and not have them in arithmetic. The fix is to push spaces and tabs into an "off-channel" stream, then reconstruct the text by looking at the start and end character indices of the first and last tokens for the text tree node. The tree is a little messier, but it does what you need.
Also, you should just name the grammar as "Context" not "ContextParser" because you end up with "ContextParserParser.java" and "ContextParserLexer.java" when you generate the parser--rather confusing. I also took liberty to remove labeling an variables (I don't used them because I work with XPath expressions on the tree). And, I reordered and reformatted the grammar to be single line, sort alphabetically in order to find rules quicker in a text editor rather than require an IDE to navigate around.
A grammar that does all this is:
grammar Content;
arithmetic: NUMBER | LPARAN arithmetic RPARAN | arithmetic POW arithmetic | arithmetic (MUL | DIV) arithmetic | arithmetic (ADD | SUB) arithmetic ;
comment: LINE_COMMENT;
content : comment | arithmetic | text ;
file: line EOF;
line: content? EOL;
start: file;
text: TEXT ;
ADD: ' ';
DIV: '/';
LINE_COMMENT: '#' STUFF | '//' STUFF;
LPARAN: '(';
MUL: '*';
NUMBER: '-'? [0-9] ;
POW: '^';
RPARAN: ')';
SUB: '-';
fragment STUFF : ~[\n\r]* ;
EOL: '\r'? '\n';
WS : [ \t] -> channel(HIDDEN);
TEXT: .; // Must be last lexer rule, and only one char in length.