Alright this is my curiosity, my question is why...
First this is the ERD to understand the tables and connections... 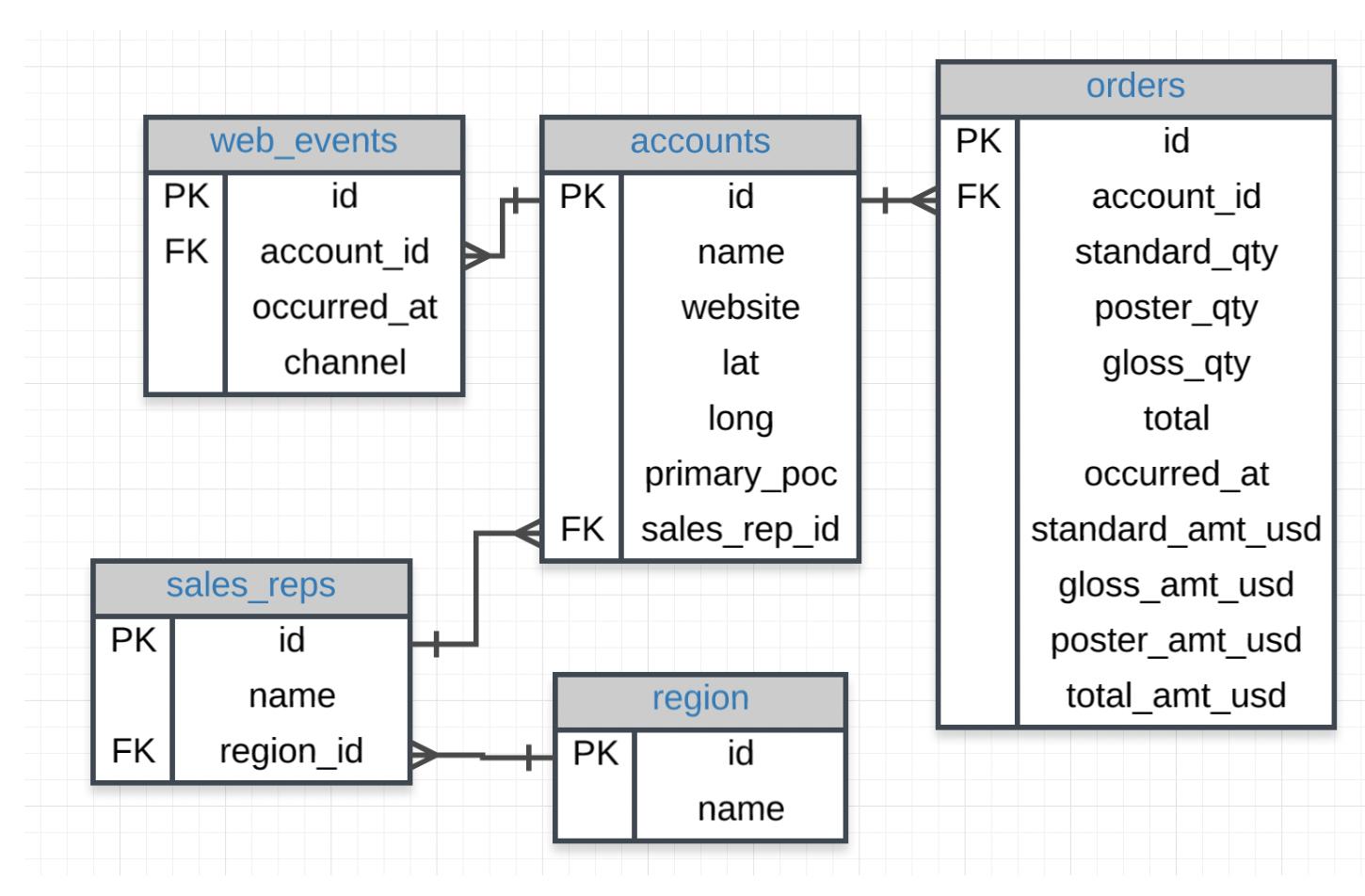
Now my Query is supposed to "Provide a table that provides the region for each sales_rep along with their associated accounts. Your final table should include three columns: the region name, the sales rep name, and the account name. Sort the accounts alphabetically (A-Z) according to account name"
I created this query:
select acc.name , reg.name , srep.name
from region reg
join sales_reps srep
on srep.region_id = reg.id
join accounts as acc
on acc.sales_rep_id = srep.id
order by 1;
This resulted in outputting only the first column of my query like so:
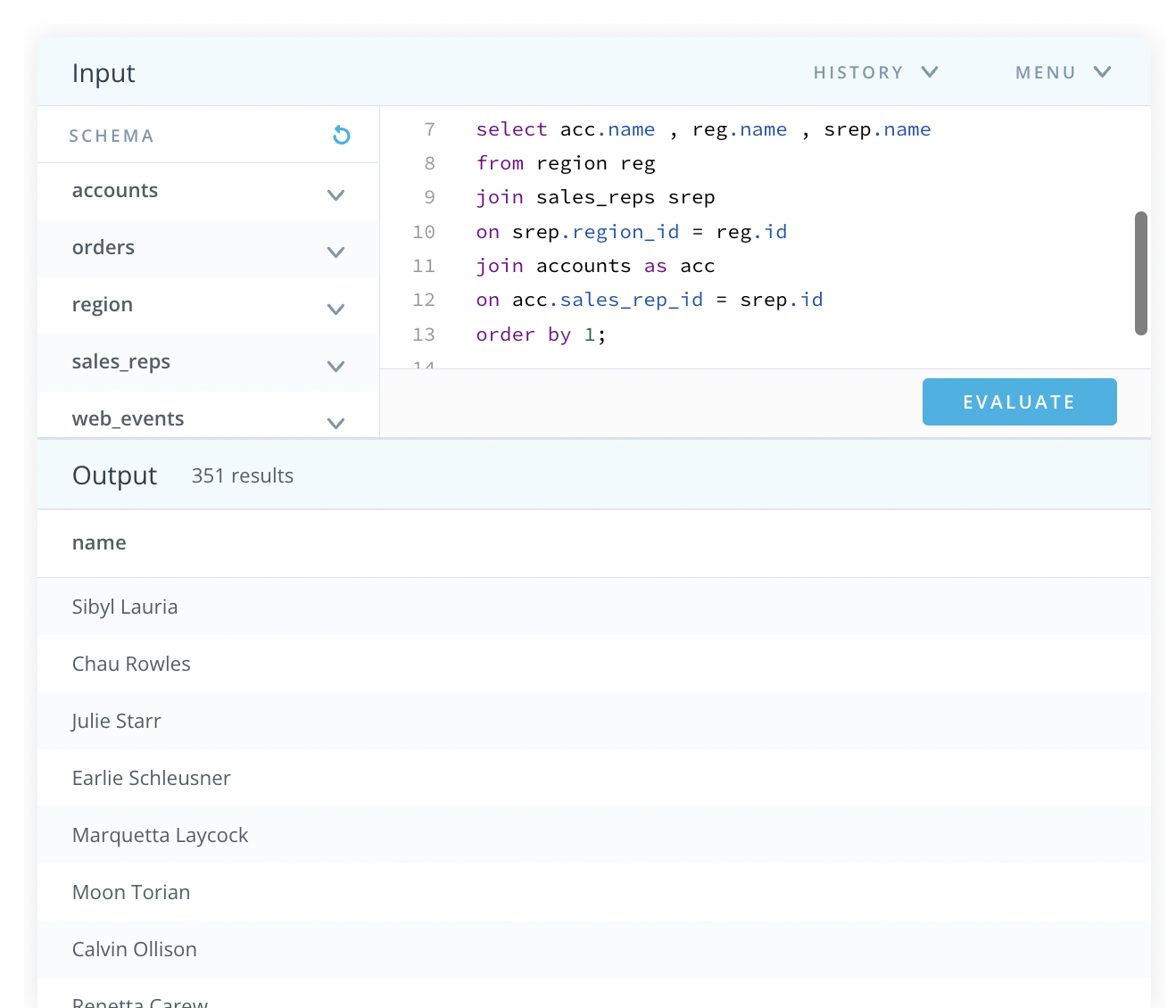
But it's not until I add aliases to each of my columns that the output is generated:
select acc.name account_name
, reg.name region_name
, srep.name sales_rep_name
from region reg
join sales_reps srep
on srep.region_id = reg.id
join accounts as acc
on acc.sales_rep_id = srep.id
order by 1;
Output:
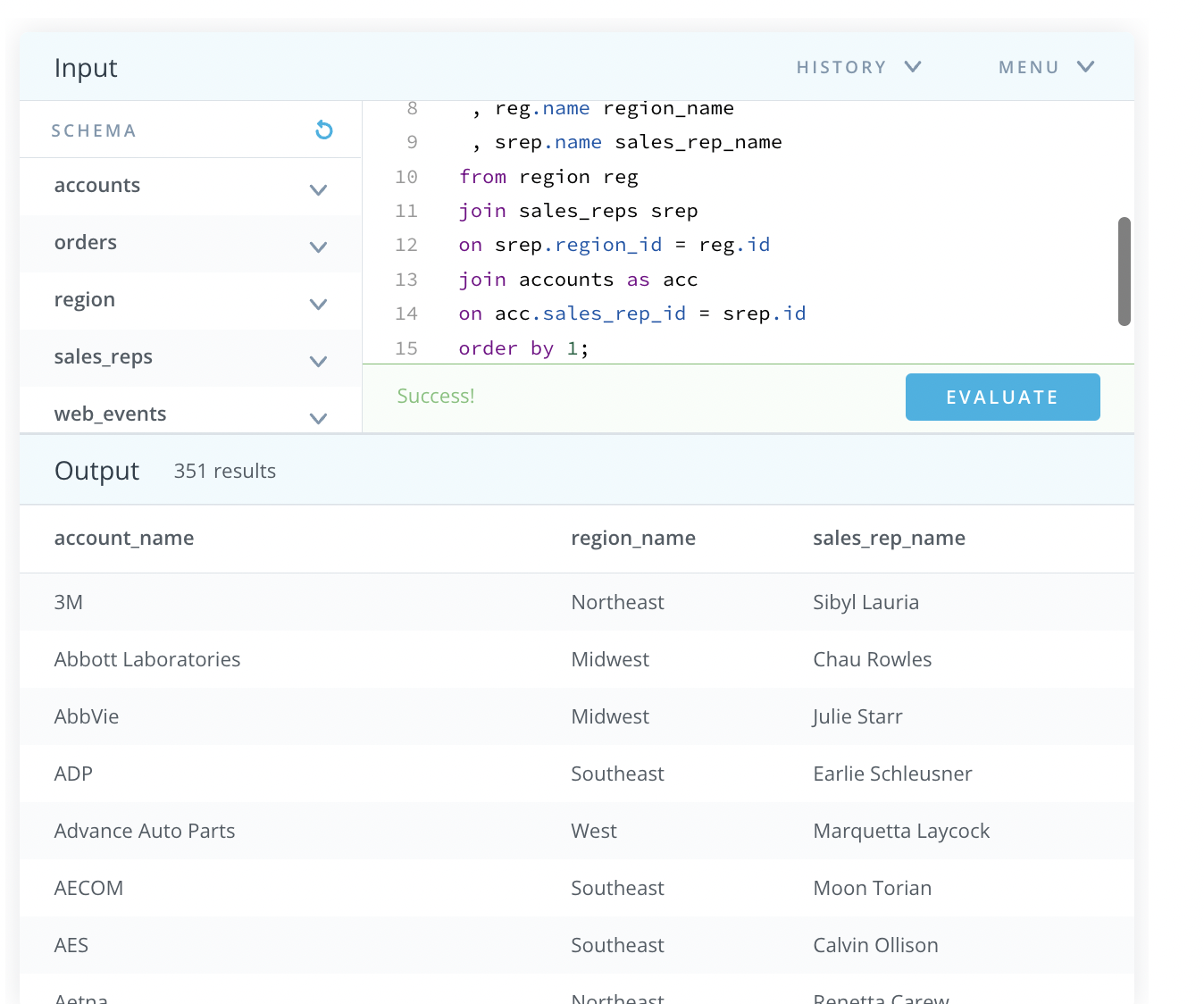
Can anyone tell me why that is ? Thank you !!!!
IMPORTANT CONTEXT INFO:This is using MODE and it's part of the SQL Course on Udacity COURSE Joins Section step 12
CodePudding user response:
You never told us what your actual SQL engine is (e.g. MySQL, SQL Server, Oracle, etc.). But this doesn't really even matter, because on most engines your first select would in fact have generated a result set with three columns all called name. You may confirm this behavior by just running your query directly against the actual SQL database.
What is likely happening here is that the Udacity SQL tool has inserted some layer in between the SQL database and the UI, the latter whose output you have been posting in your question. This additional layer is, for some reason, resolving duplicate column names in the result set by keeping only one of them. The workaround, as you have already figured out, is to just use unique aliases.