I'm trying to recognize and cut several tables
I'm trying to adapt this code that recognizes the largest table in the image, but without success
# find contours in the thresholded image and grab the largest one,
# which we will assume is the stats table
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
tableCnt = max(cnts, key=cv2.contourArea)
# compute the bounding box coordinates of the stats table and extract
# the table from the input image
(x, y, w, h) = cv2.boundingRect(tableCnt)
table = image[y:y h, x:x w]
CodePudding user response:
Tesseract is a powerful technology with CORRECT PARAMETERS. There is also an alternative way which is 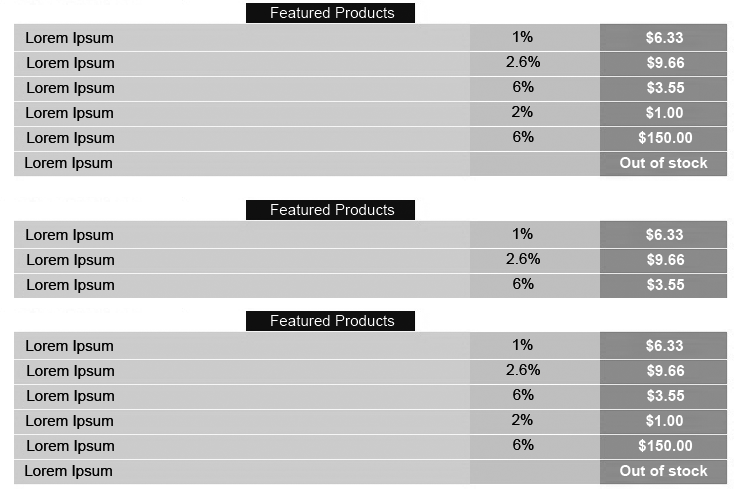
with the code:
import easyocr
reader = easyocr.Reader(['ch_sim','en']) # this needs to run only once to load the model into memory
result = reader.readtext('a.png')
print(result)
I got the results:
[([[269, 5], [397, 5], [397, 21], [269, 21]], 'Featured Products', 0.9688797744252757), ([[25, 31], [117, 31], [117, 47], [25, 47]], 'Lorem Ipsum', 0.9251252837669294), ([[513, 29], [535, 29], [535, 45], [513, 45]], '1%', 0.994760876582135), ([[643, 27], [687, 27], [687, 47], [643, 47]], '56.33', 0.9860448082309514), ([[25, 55], [117, 55], [117, 73], [25, 73]], 'Lorem Ipsum', 0.9625669229848431), ([[505, 55], [543, 55], [543, 71], [505, 71]], '2.6%', 0.9489194720877449), ([[645, 55], [687, 55], [687, 71], [645, 71]], '59.66', 0.9955955477533281), ([[25, 81], [117, 81], [117, 97], [25, 97]], 'Lorem Ipsum', 0.9347195542297398), ([[513, 79], [537, 79], [537, 95], [513, 95]], '6%', 0.9802225419827469), ([[643, 77], [687, 77], [687, 97], [643, 97]], '53.55', 0.7060389448443978), ([[25, 105], [117, 105], [117, 123], [25, 123]], 'Lorem Ipsum', 0.9813030863539253), ([[511, 105], [535, 105], [535, 121], [511, 121]], '2%', 0.96661512341383), ([[643, 105], [687, 105], [687, 121], [643, 121]], '51.00', 0.9972174551807312), ([[25, 131], [117, 131], [117, 147], [25, 147]], 'Lorem Ipsum', 0.9332194975534566), ([[637, 129], [695, 129], [695, 147], [637, 147]], '$150.00', 0.8416723013481415), ([[23, 155], [115, 155], [115, 173], [23, 173]], 'Lorem Ipsum', 0.9628505579362404), ([[619, 155], [711, 155], [711, 171], [619, 171]], 'Out Ofstock', 0.5524501407148613), ([[269, 203], [397, 203], [397, 219], [269, 219]], 'Featured Products', 0.9892802026085218), ([[25, 227], [117, 227], [117, 245], [25, 245]], 'Lorem Ipsum', 0.9816736878173294), ([[513, 227], [535, 227], [535, 241], [513, 241]], '1%', 0.7698908738878971), ([[645, 227], [687, 227], [687, 243], [645, 243]], '56.33 ', 0.5116652994056308), ([[25, 253], [117, 253], [117, 269], [25, 269]], 'Lorem Ipsum', 0.9332997726238675), ([[505, 251], [543, 251], [543, 267], [505, 267]], '2.6%', 0.5710609510357831), ([[645, 251], [687, 251], [687, 269], [645, 269]], '59.66', 0.9995503012169746), ([[25, 277], [117, 277], [117, 295], [25, 295]], 'Lorem Ipsum', 0.9626429329615878), ([[513, 277], [537, 277], [537, 293], [513, 293]], '6%', 0.9771388793180815), ([[645, 275], [687, 275], [687, 293], [645, 293]], '53.55', 0.9578577340198124), ([[269, 313], [397, 313], [397, 329], [269, 329]], 'Featured Products', 0.9701894261249253), ([[25, 339], [117, 339], [117, 355], [25, 355]], 'Lorem Ipsum', 0.9282643141918978), ([[513, 337], [535, 337], [535, 353], [513, 353]], '1%', 0.9946674557074575), ([[643, 335], [687, 335], [687, 355], [643, 355]], '56.33', 0.9876496602335217), ([[25, 363], [117, 363], [117, 381], [25, 381]], 'Lorem Ipsum', 0.9625460796304877), ([[505, 363], [543, 363], [543, 379], [505, 379]], '2.6%', 0.9337789031658965), ([[645, 363], [687, 363], [687, 379], [645, 379]], '59.66', 0.9949654211659896), ([[25, 389], [117, 389], [117, 405], [25, 405]], 'Lorem Ipsum', 0.931966914707057), ([[513, 387], [537, 387], [537, 403], [513, 403]], '6%', 0.9784907201549085), ([[643, 385], [687, 385], [687, 405], [643, 405]], '53.55', 0.5365941290893664), ([[25, 413], [117, 413], [117, 431], [25, 431]], 'Lorem Ipsum', 0.980995831244345), ([[511, 413], [535, 413], [535, 429], [511, 429]], '2%', 0.9679939124479429), ([[645, 413], [687, 413], [687, 429], [645, 429]], '51.00', 0.9964553415038925), ([[25, 439], [117, 439], [117, 455], [25, 455]], 'Lorem Ipsum', 0.9304503001919713), ([[513, 437], [537, 437], [537, 453], [513, 453]], '6%', 0.9744585914588708), ([[635, 435], [695, 435], [695, 455], [635, 455]], '$150.00', 0.9992132520533294), ([[23, 463], [115, 463], [115, 481], [23, 481]], 'Lorem Ipsum', 0.9626652609420223), ([[619, 463], [711, 463], [711, 479], [619, 479]], 'Out Ofstock', 0.5114405533530642)]
This results seems complicated because it gives the coordinates of detected texts firstly. However if you look into deeply, you will see that it is really good at detecting the texts.
This video also can help you for installation.
CodePudding user response:
Table detection may not be easily possible using just some image processing. You may have to use a deep learning model to mark the table(s).
One of the promising project is: https://github.com/Psarpei/Multi-Type-TD-TSR
You can find the colab notebook: https://github.com/Psarpei/Multi-Type-TD-TSR
Some other relevant projects:
https://github.com/deepdoctection/deepdoctection