I am scraping data using Scrapy (Python3) from a website and I would like to skip an <a> tag withing the source code because there are two and both have the same classes as you can see in the picture below:
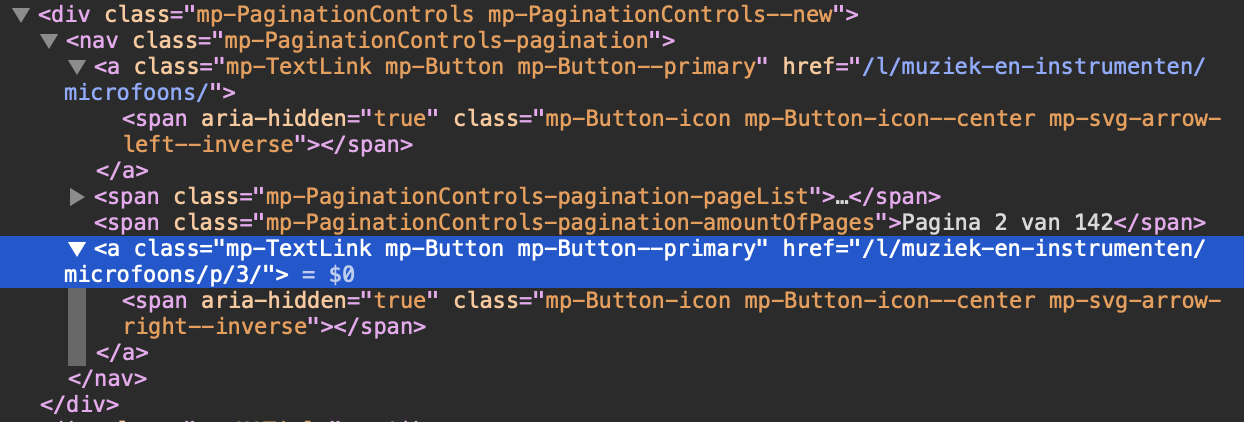
I am trying the secect the <a> tag that is highlighted in blue.
I'm using this: response.xpath("//nav[@class='mp-PaginationControls-pagination']/a/@href").get(), but that only let's me select the first <a> tag so it bugs after I'm on page two.
Here is the raw HTML:
<div >
<nav >
<a href="/l/muziek-en-instrumenten/microfoons/">
<span aria-hidden="true" ></span>
</a>
<span >
<a href="/l/muziek-en-instrumenten/microfoons/">1</a>
<span>2</span>
<a href="/l/muziek-en-instrumenten/microfoons/p/3/">3</a>
<span>...</span>
<span>142</span>
</span>
<span >Pagina 2 van 142</span>
<a href="/l/muziek-en-instrumenten/microfoons/p/3/">
<span aria-hidden="true" ></span>
</a>
</nav>
</div>
Thanks in advance
CodePudding user response:
As I see from the XML you shared the second a has different href attribute value.
But since you want to get the href value of it I guess you can't build your XPath based on it...
But below the a are span nodes, so you can find the parent a based on it.
As following:
response.xpath("//nav[@class='mp-PaginationControls-pagination']//a[./span[contains(@class,'mp-svg-arrow-right--inverse')]]/@href").get()