Assume I have the following table table and a list of interests (cat, dog, music, soccer, coding)
| userId | user_interest | label |
| -------- | -------------- |----------|
| 12345 | cat | 1 |
| 12345 | dog | 1 |
| 6789 | music | 1 |
| 6789 | soccer | 1 |
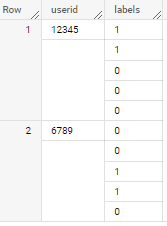
I want to transform the user interest into a binary array (i.e. binarization), and the resulting table will be something like
| userId | labels |
| -------- | -------------- |
| 12345 | [1,1,0,0,0] |
| 6789 | [0,0,1,1,0] |
I am able to do it with PIVOT and ARRAY, e.g.
WITH user_interest_pivot AS (
SELECT
*
FROM (
SELECT userId, user_interest, label FROM table
) AS T
PIVOT
(
MAX(label) FOR user_interestc IN ('cat', 'dog', 'music', 'soccer', 'coding')
) AS P
)
SELECT
userId,
ARRAY[IFNULL(cat,0), IFNULL(dog,0), IFNULL(music,0), IFNULL(soccer,0), IFNULL(coding,0)] AS labels,
FROM user_interea_pivot
HOWEVER, in reality I have a very long list of interests, and the above method in bigquery seems to not work due to
Resources exceeded during query execution: Not enough resources for query planning - too many subqueries or query is too comple
Please help to let me know if there is anything I can do to deal with this situation. Thanks!
CodePudding user response:
Still it's likely to face resource problem depending on your real data, but it is worth trying the following approach without PIVOT.
- Create interests table with additional index column first
---------- ----- -----------------
| interest | idx | total_interests |
---------- ----- -----------------
| cat | 0 | 5 |
| dog | 1 | 5 |
| music | 2 | 5 |
| soccer | 3 | 5 |
| coding | 4 | 5 |
---------- ----- -----------------
- find idx of each user interest and aggreage them like below. (assuming that user intererest is sparse over overall interests)
SELECT userId, ARRAY_AGG(idx) user_interests
FROM sample_table t JOIN interests i ON t.user_interest = i.interest
GROUP BY 1
- Lastly, create labels vector using a sparse user interest array and dimension of interest space (i.e. total_interests) like below
ARRAY(SELECT IF(ui IS NULL, 0, 1)
FROM UNNEST(GENERATE_ARRAY(0, total_interests - 1)) i
LEFT JOIN t.user_interests ui ON i = ui
ORDER BY i
) AS labels
Query
CREATE TEMP TABLE sample_table AS
SELECT '12345' AS userId, 'cat' AS user_interest, 1 AS label UNION ALL
SELECT '12345' AS userId, 'dog' AS user_interest, 1 AS label UNION ALL
SELECT '6789' AS userId, 'music' AS user_interest, 1 AS label UNION ALL
SELECT '6789' AS userId, 'soccer' AS user_interest, 1 AS label;
CREATE TEMP TABLE interests AS
SELECT *, COUNT(1) OVER () AS total_interests
FROM UNNEST(['cat', 'dog', 'music', 'soccer', 'coding']) interest
WITH OFFSET idx
;
SELECT userId,
ARRAY(SELECT IF(ui IS NULL, 0, 1)
FROM UNNEST(GENERATE_ARRAY(0, total_interests - 1)) i
LEFT JOIN t.user_interests ui ON i = ui
ORDER BY i
) AS labels
FROM (
SELECT userId, total_interests, ARRAY_AGG(idx) user_interests
FROM sample_table t JOIN interests i ON t.user_interest = i.interest
GROUP BY 1, 2
) t;
Query results

CodePudding user response:
I think below approach will "survive" any [reasonable] data
create temp function base10to2(x float64) returns string
language js as r'return x.toString(2);';
with your_table as (
select '12345' as userid, 'cat' as user_interest, 1 as label union all
select '12345' as userid, 'dog' as user_interest, 1 as label union all
select '6789' as userid, 'music' as user_interest, 1 as label union all
select '6789' as userid, 'soccer' as user_interest, 1 as label
), interests as (
select *, pow(2, offset) weight, max(offset 1) over() as len
from unnest(['cat', 'dog', 'music', 'soccer', 'coding']) user_interest
with offset
)
select userid,
split(rpad(reverse(base10to2(sum(weight))), any_value(len), '0'), '') labels,
from your_table
join interests
using(user_interest)
group by userid
with output