My code is spending most of its time scoring bisections: determining how many edges of a graph cross from one set of nodes to the other.
Assume bisect is a set of half of a graph's nodes (ints), and edges is a list of (directed) edges [ [n1 n2] ...] where n1,n2 are also nodes.
(defn tstBisectScore
"number of edges crossing bisect"
([bisect edges]
(tstBisectScore bisect 0 edges))
([bisect nx edge2check]
(if (empty? edge2check)
nx
(let [[n1 n2] (first edge2check)
inb1 (contains? bisect n1)
inb2 (contains? bisect n2)]
(if (or (and inb1 inb2)
(and (not inb1) (not inb2)))
(recur bisect nx (rest edge2check))
(recur bisect (inc nx) (rest edge2check))))
)))
The only clues I have via sampling the execution of this code (using VisualVM) shows most of the time spent in clojure.core$empty_QMARK_, and most of the rest in clojure.core$contains_QMARK_. (first and rest take only a small fraction of the time.) (See attached 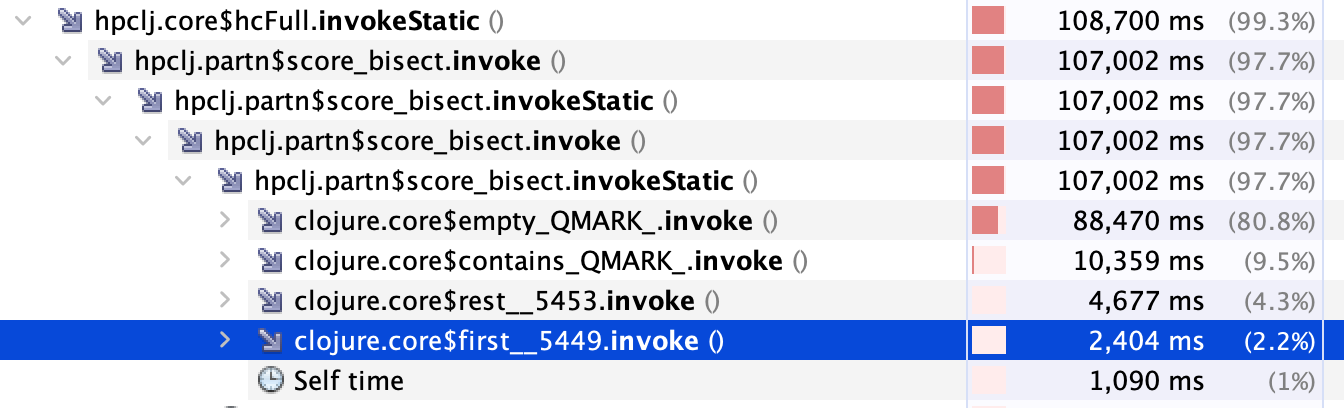 .
.
Any suggestions as to how I could tighten the code?
CodePudding user response:
First I would say that you haven't expanded that profile deep enough. empty? is not an expensive function in general. The reason it is taking up all your time is almost surely because the input to your function is a lazy sequence, and empty? is the poor sap whose job it is to look at its elements first. So all the time in empty? is probably actually time you should be accounting to whatever generates the input sequence. Almost 80% of your real workload is probably in generating the bisects, not in scoring them. So anything we do in this function can get us at most a 20% speedup, even if we replaced the whole thing with (map (constantly 0) edges).
Still, there are many local improvements to be made. Let's imagine we've determined that producing the input argument is as efficient as we can get it, and we need more speed.
- When iterating eagerly over something, use
nextinstead ofrest. The point ofrestis that it's a bit lazier, and always returns a non-nil sequence instead of peeking to see if there is a next element. If you know you will need the next element anyway, usenextto get both bits of information at once. - In general,
empty?is not an efficient way to test a sequence.(defn empty? [x] (not (seq x)))is obviously a wastednot. If you care about efficiency, write(seq x)instead, and invert yourifbranches. Better still, if you knowxis the result of anextcall, it can never be an empty sequence: only nil, or a non-empty sequence. So just write(if x ...). -
is a very expensive way to write(or (and inb1 inb2) (and (not inb1) (not inb2)))(= inb1 inb2).
So for starters, you could instead write
(defn tstBisectScore
([bisect edges] (tstBisectScore bisect 0 (seq edges)))
([bisect nx edges]
(if edges
(recur bisect (let [[n1 n2] (first edges)
inb1 (contains? bisect n1)
inb2 (contains? bisect n2)]
(if (= inb1 inb2) nx (inc nx)))
(next edges))
nx)))
Note that I've also rearranged things a bit, by putting the if and let inside of the recur instead of duplicating the other arguments to the recur. This isn't a very popular style, and it doesn't matter to efficiency. Here it serves a pedagogical purpose: to draw your attention to the basic structure of this function that you missed. Your whole function has the structure(if xs (recur (f acc x) (next xs))). This is exactly what reduce already does!
I could write out the translation to use reduce, but first I'll also point out that you also have a map step hidden in there, mapping some elements to 1 and some to 0, and then your reduce phase is just summing the list. So, instead of using lazy sequences to do that, we'll use a transducer, and avoid allocating the intermediate sequences:
(defn tstBisectScore [bisect edges]
(transduce (map (fn [[n1 n2]]
(if (= (contains? bisect n1)
(contains? bisect n2)
0, 1)))
0 edges))
This is a lot less code because you let existing abstractions do the work for you, and it should be more efficient because (a) these abstractions don't make the local mistakes you did, and (b) they also handle chunked sequences more efficiently, which is a sizeable boost that comes up surprisingly often when using basic tools like map, range, and filter.
CodePudding user response:
This answer is based this answer from amalloy and shows some additional ways to speed up this code:
- Use Java arrays:
Convert edges with (into-array (map into-array edges)). This allows you to use operations like aget, aset and especially areduce.
- Use Java functions
In the following code, I replaced = with .equals and contains? with .contains.
- Use type hints
Using these tips, I rewrote your function like this:
(defn tst-bisect-score [^HashSet bisect
^"[[Ljava.lang.Long;" edges]
(areduce edges
i
ret
(long 0)
( ret
(let [^"[Ljava.lang.Long;" e (aget edges i)]
(if (.equals ^Boolean
(.contains ^HashSet bisect
^Long (aget e 0))
^Boolean
(.contains ^HashSet bisect
^Long (aget e 1)))
0 1)))))
Convert your arguments in advance with (HashSet. ^Collection bisect) and (into-array (map into-array edges)) and then call:
(tst-bisect-score bisect edges)