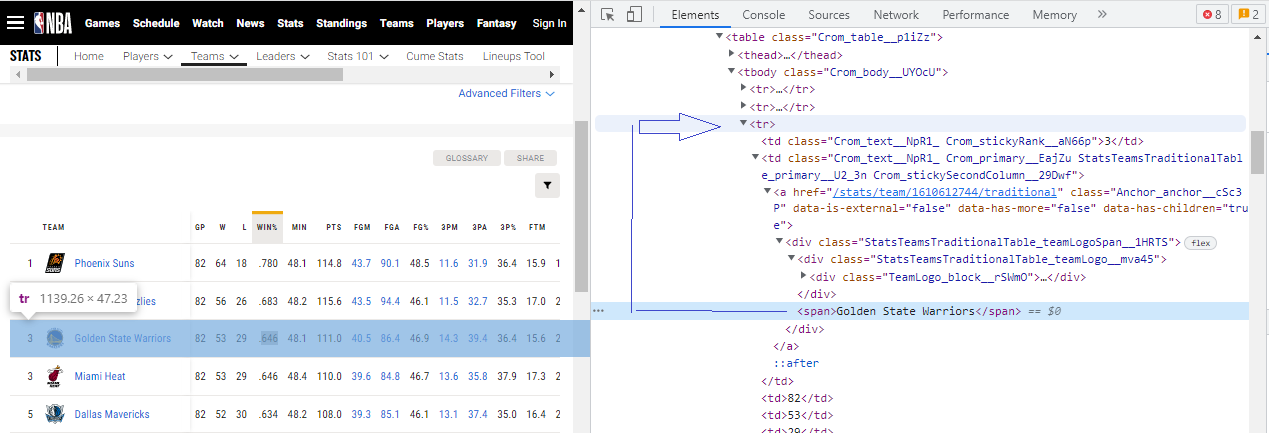
I am trying to get where first <tr> ancestor node is from <span> node.
<span> node is child of <div> which is also a <td> element child. I get to the value of <span> by finding_element with myList[1] element search. I need to get to first <tr> element.
I looked for getting ancestor nodes via XPATH. But none of them work correctly.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
options = Options()
options.add_argument("start-maximized")
webdriver_service = Service(r"C:\Users\Admin\Downloads\chromedriver_win32 (1)\chromedriver.exe")
driver = webdriver.Chrome(service=webdriver_service, options=options)
wait = WebDriverWait(driver, 5)
url = 'https://www.nba.com/schedule?pd=false®ion=1'
driver.get(url)
myList=[]
myList.append(1)
wait.until(EC.element_to_be_clickable((By.ID, "onetrust-accept-btn-handler"))).click()
elements = wait.until(EC.visibility_of_all_elements_located((By.XPATH, "//*[@data-id='nba:schedule:main:team:link']")))
for element in elements:
myList.append(element.text)
driver.get("https://www.nba.com/stats/teams/traditional")
element_to_search = wait.until(EC.visibility_of_element_located((By.LINK_TEXT, myList[1])))
classes = element_to_search.find_element(By.XPATH, "./..")
print("-works well")
print(classes.get_attribute("class"))
class_parent_tr = element_to_search.find_element(By.XPATH, "//span/ancestor::tr")#need to get <tr
print("--")
print(class_parent_tr.get_attribute("class"))
class_parent_tr_02 = element_to_search.find_element(By.XPATH, "//tr[.//span[text()='Golden State Warriors']]")#need to get from here to node<tr. I took the text from a list myList[1], and wrote it as a text
print("---")
print(class_parent_tr_02.get_attribute("class"))
result=class_parent_tr.find_element(By.XPATH("//td[6]"))#
print(result.text)
driver.quit()
CodePudding user response:
With XPath you can locate parent element based on child element.
Especially since here you are going to locate a tr element based on text content of some of it's child elements.
All what you need here is as following:
driver.get("https://www.nba.com/stats/teams/traditional")
xpath_template = "//tr[contains(.,'{0}')]"
xpath = xpath_template.format(myList[1])
tr = driver.find_element(By.XPATH, xpath)
xpath here is a XPath expression dynamically built based on the text contained in myList[1]
The actual value of xpath is "//tr[contains(.,'Golden State Warriors')]"
tr is getting the desired element on the page.
UPD
This is my code:
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
options = Options()
options.add_argument("start-maximized")
webdriver_service = Service('C:\webdrivers\chromedriver.exe')
driver = webdriver.Chrome(service=webdriver_service, options=options)
wait = WebDriverWait(driver, 10)
url = 'https://www.nba.com/schedule?pd=false®ion=1'
driver.get(url)
myList=[]
myList.append(1)
wait.until(EC.element_to_be_clickable((By.ID, "onetrust-accept-btn-handler"))).click()
elements = wait.until(EC.visibility_of_all_elements_located((By.XPATH, "//*[@data-id='nba:schedule:main:team:link']")))
for element in elements:
myList.append(element.text)
driver.get("https://www.nba.com/stats/teams/traditional")
xpath_template = "//tr[contains(.,'{0}')]"
xpath = xpath_template.format(myList[1])
tr = driver.find_element(By.XPATH, xpath)
text_content = tr.find_element(By.XPATH, ".//td[6]").text
print(text_content)
And this is the output
.646
To get the 6-th td inside the tr you need to use the dot . infront of the XPath expression. Otherwise it will search from the top of the page.