get_attribute() method in python selenium gives an error ?Did you mean 'getattribute'. Why I need that?
I am trying to get parent elements class attribute to know if got to right dom place.
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from datetime import datetime
#import pandas as pd
driver = webdriver.Chrome(r"C:\Users\Admin\Downloads\chromedriver_win32 (1)\chromedriver.exe")
driver.get("https://www.nba.com/schedule?pd=false®ion=1")
driver.implicitly_wait(5)
element_to_click=driver.find_element(By.ID,"onetrust-accept-btn-handler") #.click()
element_to_click.click()
element_to_save=driver.find_element(By.XPATH,"//div/div/div/div/h4")
#element_to_save.to_excel("3row,3column)")
f=open('result_file00.txt','r ')
f.write(element_to_save.text)
f.write("\n")
f.write(str(datetime.today()))
myList=[]
myList.append(1)
elements_to_save=driver.find_elements(By.XPATH,"//*[@data-id='nba:schedule:main:team:link']")
for element in elements_to_save:
f.write(" ")
f.write(element.text)
myList.append(element.text)
f.write(" \n ")
f.write(str(datetime.today()))
f.close()
f=open('result_file00.txt','r ')
print(f.read())
f.close()
print(myList)
print(type(myList))
time.sleep(1)
driver.get("https://www.nba.com/stats/teams/traditional")
element_to_search=driver.find_element(By.LINK_TEXT,myList[1])
parentof_element_to_search=element_to_search.parent
print(parentof_element_to_search.get_attribute("class")) #error giving line
driver.quit()
I tried parentof_element_to_search=element_to_search.find_element(By.XPATH("..")) to get parent element. Then trying to get parent class of that element with parentof_element_to_search.get_attribute("class") resulted with same error.
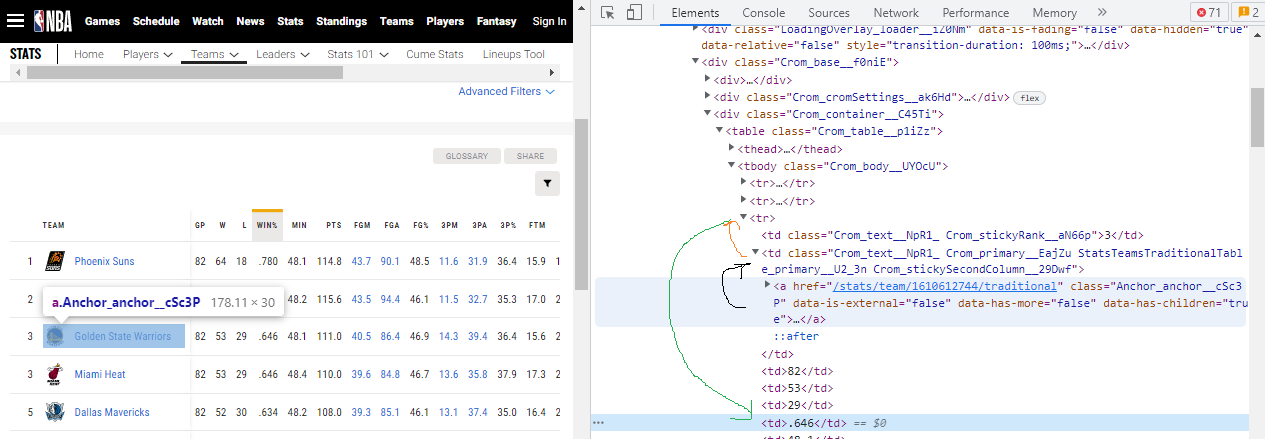
My desired code snippet from this result is getting value of 6-th <td element in that<tr.
find_element(By.XPATH("//td[6]") the green line in photo.
In brief, I get the team name's <td line, then coming back to the same <tr tag and getting 6 step for <td value.
CodePudding user response:
You not actually getting the parent element with parentof_element_to_search=element_to_search.find_element(By.XPATH(".."))
Try this instead:
parent_of_element_to_search=element_to_search.find_element(By.XPATH("./.."))
Now you will be able to apply get_attribute() on it like the following:
parent_of_element_to_search=element_to_search.find_element(By.XPATH("./.."))
parent_element_classes = parent_of_element_to_search.get_attribute("class")
UPD
This is what I tried
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
options = Options()
options.add_argument("start-maximized")
webdriver_service = Service('C:\webdrivers\chromedriver.exe')
driver = webdriver.Chrome(service=webdriver_service, options=options)
wait = WebDriverWait(driver, 10)
url = 'https://www.nba.com/schedule?pd=false®ion=1'
driver.get(url)
myList=[]
myList.append(1)
wait.until(EC.element_to_be_clickable((By.ID, "onetrust-accept-btn-handler"))).click()
elements = wait.until(EC.visibility_of_all_elements_located((By.XPATH, "//*[@data-id='nba:schedule:main:team:link']")))
for element in elements:
myList.append(element.text)
driver.get("https://www.nba.com/stats/teams/traditional")
element_to_search = wait.until(EC.visibility_of_element_located((By.LINK_TEXT, myList[1])))
classes = element_to_search.find_element(By.XPATH, "./..").get_attribute("class")
print(classes)
And this is the output of my program run
Crom_text__NpR1_ Crom_primary__EajZu StatsTeamsTraditionalTable_primary__U2_3n Crom_stickySecondColumn__29Dwf