I have a situation where I want to find the maximum date that is prior to the current date and then get the highest and lowest test scores for that date, adding them to the dataframe and creating new columns
So - starting with the following:
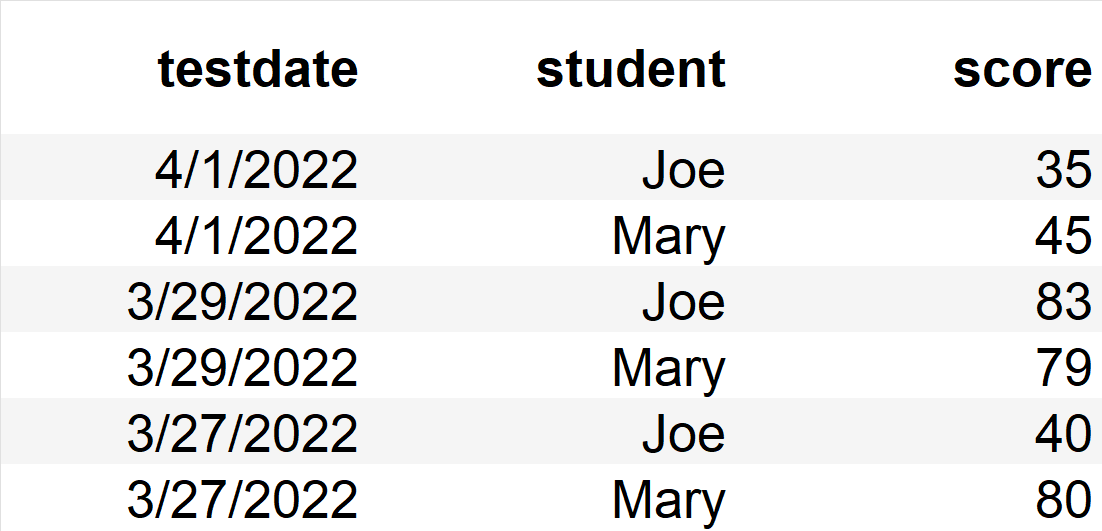
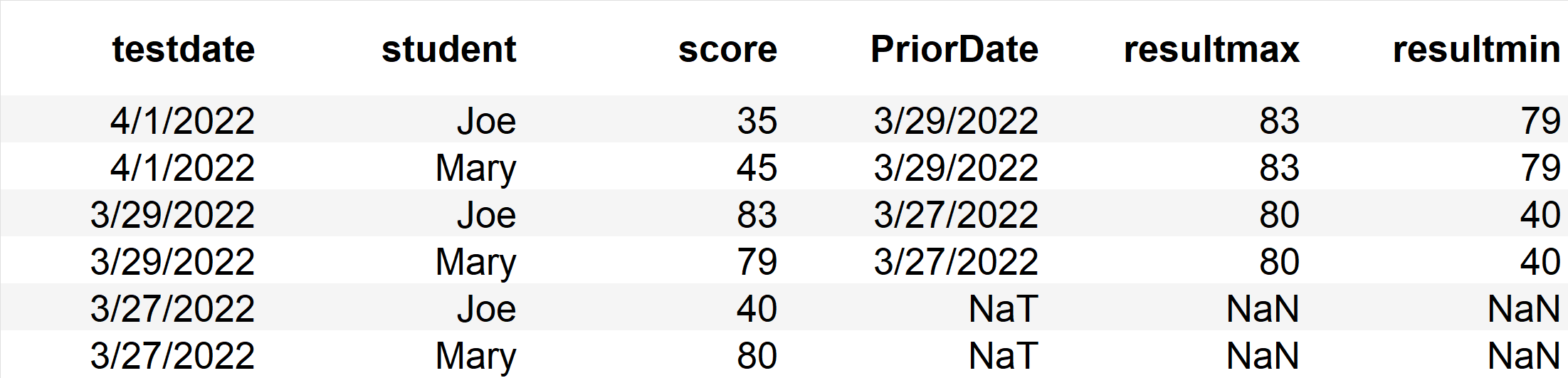
I would like to end up with something like this:
The code below does work, but my data set is huge and I am hoping there is a more efficient/faster way to achieve the same objective as I need it to run faster
Any help would be greatly appreciated
Thanks!
def findMax(x):
import numpy as np
larger = frame.testdate[frame.testdate < x]
if len(larger) != 0:
return max(larger)
else:
return np.nan
def scorerange(row):
x=frame.loc[frame['testdate'] == row.PriorDate]
return x.score.max(),x.score.min()
import pandas as pd
data = {'testdate' : ['2022-04-01', '2022-04-01', '2022-03-29', '2022-03-29','2022-03-27', '2022-03-27'],
'student' : ['Joe', 'Mary', 'Joe', 'Mary', 'Joe', 'Mary'],
'score' : [35, 45, 83,79,40,80]}
frame = pd.DataFrame(data)
frame.testdate=pd.to_datetime(frame.testdate)
frame['PriorDate']=frame.testdate.apply(findMax)
frame['resultmax'],frame['resultmin'] = zip(*frame.apply(scorerange, axis=1))
frame
Note that the following will work also - I can replace both functions with one and do it all in one shot
def findall(x):
import numpy as np
larger = frame.testdate[frame.testdate < x]
if len(larger) != 0:
x=frame.loc[frame['testdate'] == max(larger)]
return max(larger),x.score.max(),x.score.min()
else:
return np.nan,np.nan,np.nan
frame['PriorDate'],frame['resultmax'],frame['resultmin'] = zip(*frame.testdate.apply(findall))
CodePudding user response:
Try this on larger dataset. The (hopeful) advantage here for "large" data is that you make one pass (O(n)) over all of the data and get what you need to construct the result and store the values in constant-time access dictionaries.
My theory is that when you are using the pandas construct, it has to do logical checks "for each" date and across all other dates (O(n^2)) and similarly for scores, etc. which is expensive, even if vector-ized.
Comment back and let me know how this goes and include the size of your full dataset for info.
Assumptions/observations:
- no error checking here for ill-constructed data
- no need to convert dates as alphanumeric sort works
- the input data is sorted by date: see note in code
Code
import pandas as pd
data = {'testdate' : ['2022-04-01', '2022-04-01', '2022-03-29', '2022-03-29','2022-03-27', '2022-03-27'],
'student' : ['Joe', 'Mary', 'Joe', 'Mary', 'Joe', 'Mary'],
'score' : [35, 45, 83,79,40,80]}
# we can use pandas to convert... if needed
df = pd.DataFrame(data)
records = df.to_records()
# take a peek...
print(records[:2])
# a worthy goal here seems to be to make ONE PASS over the data and get everything needed...
d_max = {} # the max score by date, on NaN
d_min = {} # the min score by date, or NaN
d_prior = {} # the prior date
# this construct ASSUMES that the dates are sorted as in the example
# if not, you could EITHER sort by date, or use same construct as the scores...
last_date = None
for r in records:
d = r[1]
curr_max = d_max.get(d) # returns None if not found...
curr_min = d_max.get(d)
curr_prior = d_prior.get(d)
d_max[d] = max(r[3], curr_max) if curr_max else r[3]
d_min[d] = min(r[3], curr_min) if curr_min else r[3]
if d != last_date:
if last_date:
d_prior[last_date] = d
last_date = d
# build the new records and push to new df (if desired)
result = [] # to catch result
for r in records:
prior_day = d_prior.get(r[1])
new_r = (r[1], r[2], r[3], prior_day, d_max.get(prior_day), d_min.get(prior_day))
result.append(new_r)
df2 = pd.DataFrame.from_records(result,
columns=['testdate','student', 'score', 'prior_date', 'max', 'min'])
print(df2)
Output
[(0, '2022-04-01', 'Joe', 35), (1, '2022-04-01', 'Mary', 45)]
testdate student score prior_date max min
0 2022-04-01 Joe 35 2022-03-29 83.0 79.0
1 2022-04-01 Mary 45 2022-03-29 83.0 79.0
2 2022-03-29 Joe 83 2022-03-27 80.0 40.0
3 2022-03-29 Mary 79 2022-03-27 80.0 40.0
4 2022-03-27 Joe 40 None NaN NaN
5 2022-03-27 Mary 80 None NaN NaN
Follow-up
A quick bit of test code on this shows it does 1M records in 11sec. Tried with the "original" way and stopped it at about 20 minutes... :(